2015년에 발표된 본 논문은 Auto Encoder를 활용하여 협업필터링을 진행하는 모델인 AutoRec에 대하여 소개하고 있습니다.
Collaborative filtering
컨텐츠 기반(content-based) 방법과 더불어 추천시스템의 한가지 큰 줄기인 협업 필터링(Collaborative Filtering)은 컨텐츠 기반 필터링처럼 유저, 아이템의 profile을 따로 만들 필요 없이, 평점과 방문기록 등의 과거 상호관계(interaction)에 기반하여 추천을 제공합니다.
예를들어 협업필터링은 "유저 A와 B가 아이템 1에 대하여 비슷한 평가를 내렸다면, 유저 A가 선호하는 다른 아이템인 2에 대해서도 유저 B가 비슷한 선호도를 가지고 있지 않을까?" 라는 생각과 같습니다.
일반적인 협업필터링 상황은 m명의 User, n개의 Item에 대한 partially observed User-Item rating matrix \(R \in \mathbb{R^{m\times n}}\)이 존재합니다.

실제 상황에서는 User와 Item이 매우 많기 때문에, 모든 유저가 모든 아이템에 대해 평점을 내린 경우는 드물다고 할 수 있습니다.
따라서 대부분의 Rating Matrix는 partially observed 상황의 sparse한 Matrix입니다.
협업 필터링은 기록에 없는 User-Item 조합에 대한 예측을 진행합니다. 이러한 이유에서 협업 필터링은 Matrix Completion Task로 표현되기도 합니다.
협업 필터링에 대한 조금 더 자세한 설명을 아래의 리뷰에 기술하여 두었습니다. 참고 부탁드립니다.
[paper review][추천시스템]Matrix Factorization Techniques for recommender systems
Recommender System 정보가 넘쳐나는 현 시대에서 추천 시스템은 전자 상거래, 온라인 뉴스 및 소셜 미디어 사이트를 포함한 많은 온라인 서비스에 널리 채택되어 기호에 맞는 상품을 제공하고 있습
supkoon.tistory.com
Auto Encoder
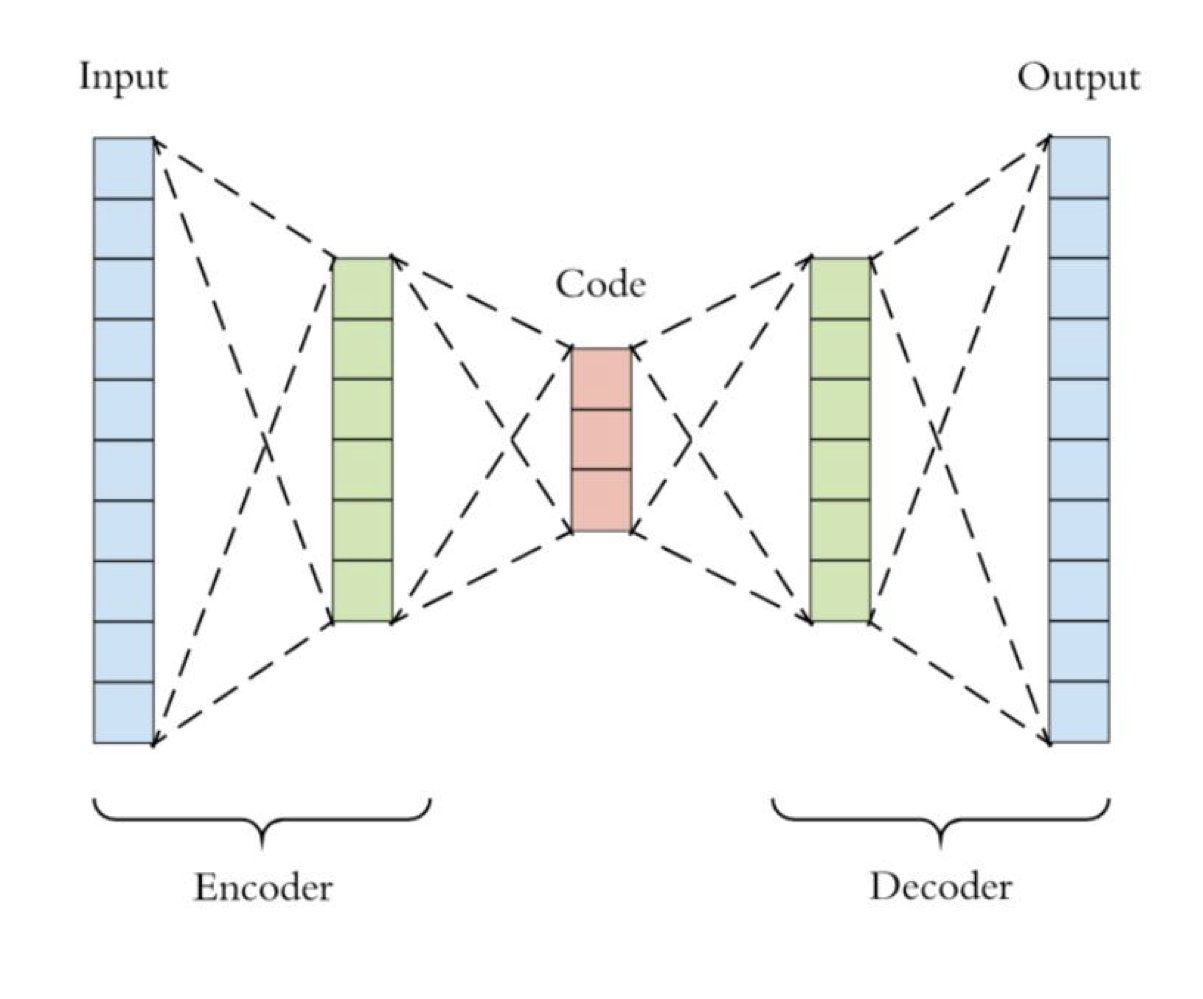
Auto Encoder는 동일한 입, 출력 구조를 사용해 압축된 latent representation을 학습할 수 있는 비지도 학습 모델입니다.
따라서 Auto Encoder는 Encoder와 Decoder로 구성되어 서로 대칭을 이루는 구조를 가지고 있습니다.
학습은 일반적으로 모델 Output과 Input 사이의 RMSE를 최소화하는 방향으로 진행됩니다.
$$Encoder\,\, \phi : X \rightarrow F$$
$$Decoder\,\, \varphi : F \rightarrow X$$
$$\phi, \varphi = argmin||X-(\phi \circ \varphi)X||_2^2$$
학습이 완료된 Auto Encoder는 분리를 통해 다양한 쓰임새로 사용될 수 있습니다.
Encoder \(\phi\)는 저차원 Latent space로의 임베딩을 위해 사용될 수 있으며, Decoder는 generative model로서 사용이 가능합니다.
간단하지만 강력한 성능을 가지고 있기 때문에, Auto encoder의 다양한 Variation 구조들이 Vision, Speech 등 다양한 분야에서 사용되고 있습니다.
노이즈에 일반화된 성능을 보여주는 Denoising Auto Encoder, 이미지를 학습하는 Convolutional Auto Encoder,
시퀀스를 학습하는 RNN Auto Encoder, 정규분포를 사용하여 latent feature를 가정하는 Variational Auto Encoder는 대표적인 Auto Encoder 구조의 예시입니다.
1. AutoRec
AutoRec은 Auto Encoder를 협업 필터링에 적용한 모델로서,
Auto Encoder의 장점에 힘입어 기존의 협업필터링 모델에 비해 Representation과 Complexity 측면에서 뛰어난 모습을 보여줍니다.
Model architecture
유저, 아이템 등의 특성을 Latent space로 매핑하는 것은 협업필터링에서 특성간의 Interaction을 모델링하기 위해 대중적으로 사용되는 방법 중 하나입니다. 앞서 리뷰를 진행하였던 추천시스템 모델인 MF, NCF, FM, DeepFM, Wide&deep은 서로 다른 방법론 속에서도 부분적으로는 Latent Factor를 사용하고 있습니다.
AutoRec 또한 Auto Encoder를 사용하여 유저 또는 아이템 벡터를 저차원의 Latent feature로 표현하는 방법으로,
partially observed User-Item rating matrix \(R \in \mathbb{R^{m\times n}}\)에 대한 Matrix Completion을 수행합니다.
일반적인 Latent Factor 모델과 달리, AutoRec은 아이템, 유저 중 하나에 대한 임베딩만을 진행합니다.
저자들은 아이템을 임베딩하는 Item-based 구조를 I-AutoRec, 유저를 임베딩하는 user-based 구조를 U-AutoRec으로 명명하였습니다. 두가지 모델에 대한 방법은 동일하기 때문에 I-AutoRec을 기준으로 설명 드리도록 하겠습니다.
아이템 \(i \in I = \{1...n\}\)이 존재할 때,
각각의 아이템 i에 대한 평점 \(r^{(i)}\)는 모든 유저 \(u \in U = \{1...m\}\)와의 조합으로 아래와 같이 존재할 수 있습니다.
$$r^{(i)} = (R_{1i},...R_{mi}) \in \mathbb{R}^m$$
그리고 실제 데이터 \(r^{(i)}\)에는 관측되지 않은 조합과 관측된 조합들이 혼재되어 있을 것 입니다.
I-AutoRec은 각각의 아이템 i에 대한 rating vector \(r^{(i)}\)를 Auto-Encoder의 Input으로 합니다.
일반적인 Auto Encoder와 동일하게 AutoRec은 다음과 같은 Encoder & Decoder reconstruction 과정을 수행합니다.
$$h(r;\theta) = f(W \cdot g(Vr + \mu)+b$$
\(\theta=\{W,V,\mu,b\}\)는 모델의 파라미터이며, \(f(\cdot),g(\cdot)\)은 activation function입니다.
\(W \in \mathbb{R}^{m\times k},V\in \mathbb{R}^{k\times m}\) 는 각각 Encoder와 Decoder의 Weight Matrix를,
\(\mu \in \mathbb{R}^k,b\in \mathbb{R}^m\)는 Encoder와 Decoder의 bias를 의미합니다.
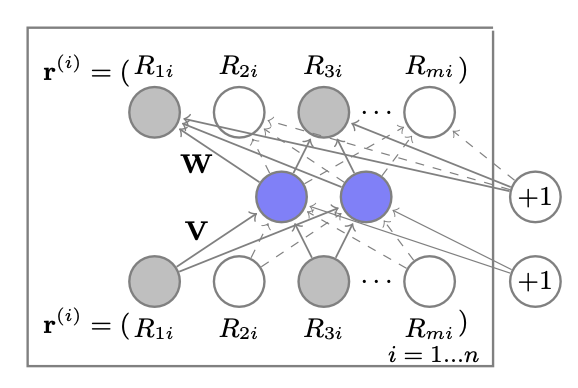
위의 그림은 하나의 아이템에 대한 AutoRec 구조를 보여줍니다. 하지만 n개 만큼의 AutoRec 구조가 존재하는 것은 아닙니다. 모든 개별적인 아이템에 대한 AutoRec은 파라미터를 공유하는 하나의 모델입니다.
Training
AutoRec은 일반적인 Auto Encoder와 동일하게 RMSE를 최소화 하는 방향으로 학습을 진행합니다.
$$\min_{\theta}\sum_{r\in S} ||r-h(r;\theta)||_2^2$$
이 때 중요한점은, 관측되지 않은 데이터에 대해서는 역전파를 진행하지 않고, 관측된 데이터의 파라미터에 대해서만 역전파를 통해 업데이트가 된다는 것 입니다.
이전의 그림을 다시 살펴보겠습니다.
회색 플레이트는 관측된 데이터, 흰색 플레이트는 관측되지 않은 데이터를 의미합니다.
관측된 데이터에 해당하는 회색 플레이트의 Connection은 실선의 형태로 업데이트를 진행하며,
관측되지 않은 데이터인 흰색 플레이트의 Connection은 점선으로 표시하여 업데이트 하지 않는다는 것을 알 수 있습니다.
또한 오버피팅을 방지하기 위해 정규화 항을 최적화식에 추가할 수 있습니다.
다음은 최종적인 AutoRec의 목적함수입니다.
$$\min_{\theta}\sum_{i=1}^n||r^{(i)}-h(r^{(i)};\theta)||_{O}^2+ {\lambda\over 2}\cdot(||W||_F^2+||V||_F^2)$$
\(||\cdot||_O^2\) 는 관측된 데이터(Observed data)에 대해서만 RMSE를 계산함을 의미합니다.
학습이 진행되는 파라미터는 \(2mk+m+k\)개 입니다.
Encoder, Decoder가 각각 mk개의 임베딩 파라미터를 갖고, bias를 위해 m, k개의 파라미터가 사용됩니다.
기존의 협업필터링에 비하여 굉장히 적은 파라미터가 필요함을 알 수 있습니다.
(Auto Encoder는 Encoder와 Decoder의 파라미터를 묶는경우도 존재하기 때문에, 약간의 성능하락을 감수한다면, 더욱 파라미터 수를 줄일 수 있을 것이라고 생각됩니다.)
최종적으로 학습된 파라미터를 통해 I-AutoRec이 예측하는 평점은 다음과 같습니다.
$$\hat{R_{ui}} = (h(r^{(i)};\hat{\theta})_u$$
유저 기반의 U-AutoRec은 아래의 가정에서 출발하여 동일하게 진행하시면 됩니다.
유저 \(u \in U = \{1...m\}\)
유저 u와 모든 아이템의 평점 조합 \(r^{(u)} = (R_{u1},...R_{un}) \in \mathbb{R}^n\)
Comparison
대표적인 Latent Factor 모델인 MF와의 간단한 비교를 진행해 보겠습니다.
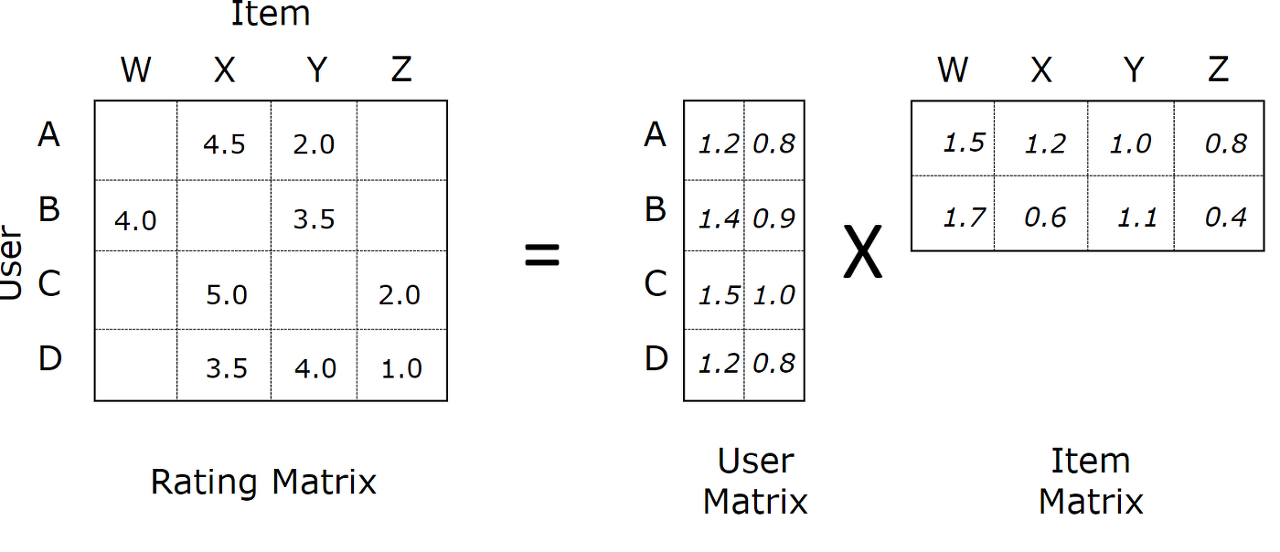
MF는 SVD와 유사한 방법으로 각기 다른 차원의 User, Item Matrix를 동시에 Latent space로 매핑합니다.
하지만 앞서 말씀드린대로, AutoRec은 I-AutoRec, U-AutoRec 각각의 형태에서 유저와 아이템 중 하나만을 매핑합니다.
어떠한 방법이 옳다라는 판단을 내릴수는 없지만, 서로 다른 방법을 사용하고 있음을 알 수 있습니다.
또한 MF가 Linear한 저차원의 Latent representation과 Interaction을 학습하는 반면,
AutoRec은 non-linear한 Activation Function을 사용하여 복잡한 non-linear latent representation을 학습할 수 있습니다.
(이전의 DeepFM 논문의 experiments에서 high-order Interaction을 학습하는 모델들이 low-order Interaction을 학습하는 모델에 비해서 모두 좋은 성능을 보였기 때문에, 이 점에 있어서는 AutoRec이 조금 더 낫지않나 하는 생각이 들었습니다.)
2.Results
모델 검증을 위한 과정에는 Movielens dataset과 Netflix dataset이 사용되었으며 다음 네가지 실험이 진행되었습니다.
result 1.
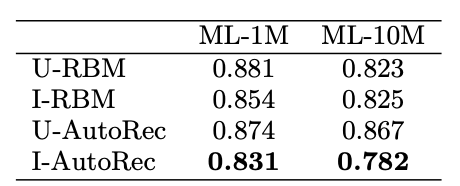
첫번째 실험은 User based 모델과 Item based 모델의 성능 비교입니다.
비교모델과 AutoRec 모두 Item based 모델의 성능이 좋았음을 알 수 있습니다.
이는 rating per user보다 rating per Item이 상대적으로 높은 경우가 많았기 때문이라고 합니다.
또한 I-AutoRec의 성능이 가장 좋았음을 확인할 수 있습니다.
result 2.

두번째 실험은 비 선형의 latent feature를 학습하는게 정말 도움이 되었는지를 검증하는 실험입니다.
hidden layer에 비 선형성을 추가시켜주는 sigmoid \(g(\cdot)\)의 사용이 AutoRec의 성능에 큰 영향을 준다는 사실을 알 수 있습니다.
result 3.
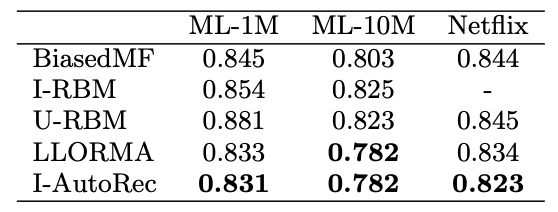
당시 쓰이던 모든 Baseline들과의 성능 비교입니다. I-AutoRec이 가장 낮은 RMSE를 달성하였습니다.
result 4.
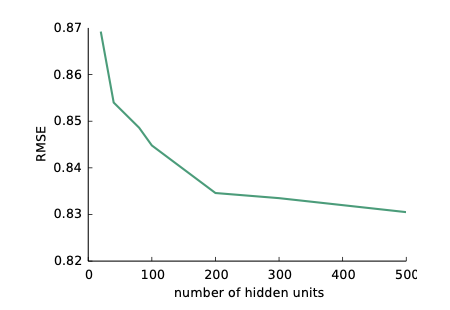
히든 유닛의 수에 따른 RMSE의 성능을 비교해 보았습니다.
깊게 AutoRec을 만드는 것이 성능 향상에 도움을 준다는 사실을 말해주고 있습니다.
3.구현
GitHub - supkoon/AutoRec-tf
Contribute to supkoon/AutoRec-tf development by creating an account on GitHub.
github.com
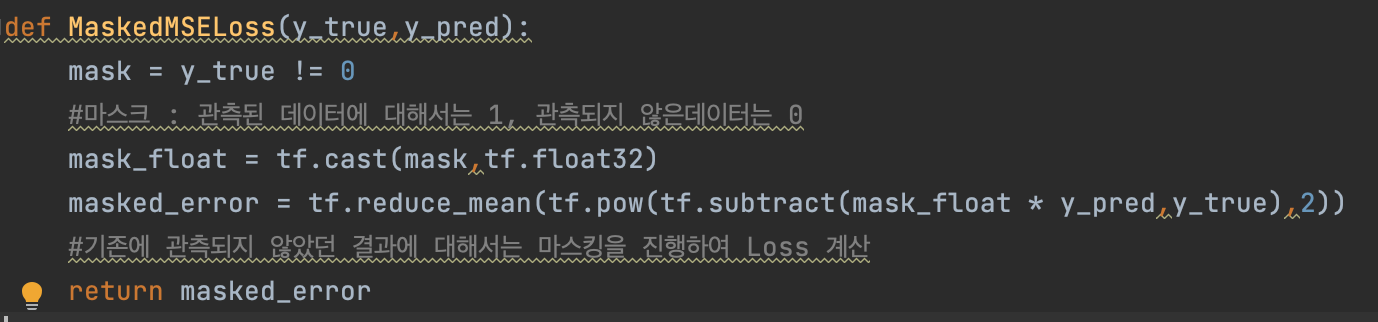
AutoRec에 대한 구현을 진행해 보았습니다. 관측되지 않은 데이터에 대해서는 마스킹을 진행하여 MSELoss를 계산하였습니다.
논문과 같은 MovieLens-1M 데이터를 활용하였는데, 어느정도 비슷한 결과가 나오는것 같습니다. 감사합니다.
마무리
AutoRec은 Auto Encoder를 사용하여 특성을 Latent space로 매핑하는 협업 필터링 방법입니다.
비록 간단한 논문이지만, 기존의 방법들을 다른 시각에서 접근하여 우수한 성능을 보였다는 점이 좋게 느껴졌습니다.
특히 Auto Encoder라는 방법을 처음 추천시스템에 사용하였다는 점이 큰 Contribution인 것 같습니다. 감사합니다.