본 논문은 2017년 발표된 논문으로 앞서 리뷰하였던 Factorization Machines을 신경망으로 확장한 DeepFM 모델을 제안하고 있습니다. DeepFM은 추천시스템에서 중요시되는 CTR 예측을 위한 모델로서, 기존의 모델들의 장점들을 잘 취합한 모델이라고 할 수 있습니다.
CTR(Click-through rate) in Recommender system

CTR(Click-through rate)이란 추천된 아이템을 유저가 클릭할 확률을 의미합니다.
추천시스템에 있어 CTR(Click-through rate)의 예측은 매우 중요한 요소 중 하나입니다. 대부분의 추천시스템은 CTR의 최대화를 목표로 하고 있습니다.
CTR의 예측을 위해서는 클릭 이전에 숨겨진 사용자의 Implicit feature를 학습해야 합니다.
본 논문의 저자들은 실험을 통하여 유저들이 식사 시간(시간)에 음식 배달 앱(앱 종류)을 자주 다운로드한다는 사실을 발견하였으며,
이는 앱 종류와 시간 사이의 order-2 Interaction이 CTR의 신호가 되었음을 알 수 있는 예시입니다.
또한, 남자(성별) 아이들(나이)이 슈팅게임 어플(앱 종류)과 RPG 게임 어플(앱 종류)을 좋아한다는 사실은 성별, 나이, 앱 종류 사이의 order-3 interaction이 CTR에 신호가 될 수 있음을 보여주는 예시가 됩니다.
이러한 Implicit feature 사이의 Interaction은 보통 매우 복잡하며, 양질의 추천을 위해서는 낮은 차원의 Interaction부터 고차원의 Interaction이 모두 중요하게 고려되야 합니다.
다양한 차원의 Interaction을 고려하는 것이 추천시스템의 성능을 끌어올려준다는 것은 Wide & Deep 과 FM의 연구를 통해서도 알 수 있었습니다.
앞선 두가지의 예시는 누구나 납득할만한 Interaction이며, 전문가를 고용하여 모델링 할 수 있습니다.
하지만, '기저귀를 구매하는 사람은 맥주를 함께 구매한다(order-2)'와 같은 대부분의 Interaction들은 데이터 속에 숨겨져있어 전문가조차도 쉽사리 찾을 수 없습니다. (아버지들이 기저귀를 자주 구매하는 듯 합니다.)
사실 아무리 이해하기 쉬운 Interaction들이 존재한다 하더라도, 인력을 사용하여 기하급수적으로 늘어나는 모든 Interaction을 모델링할 수는 없습니다. 따라서 CTR을 증가시키기 위해서는 머신러닝 모델을 사용하여 특성간의 다양한 Interaction을 포착할 수 있어야 합니다.
Related studies
2010년 발표된 FM(Factorization Machines)은 Latent space로 각각의 특성들을 매핑하여 내적을 통해 Interaction을 계산할 수 있는 방법입니다.

FM의 factorized parametrization은 order-2에서부터 order-n까지의 Interaction을 내적을 통해 모두 모델링 할 수 있게 합니다.
FM이 Linear complexity를 갖고있다고는 하지만, 실제로는 높은 복잡도로 인하여 High-order가 아닌 order-2 모델링이 주로 사용됩니다.
2016년 발표된 구글의 Wide & deep 은 Linear("wide") 모델과 neural network("Deep") 모델을 합친 구조로서, low-order와 high-order Interaction을 모두 모델링할 수 있었습니다.
하지만 Wide&deep 구조는 high-order Interaction을 모델링하기 위해 직접 선정한 feature를 cross-product transformation 하여 새로운 특성으로 추가하는 방법을 채택하고 있습니다.

추천시스템이 여전히 전문화된 feature engineering을 필요로 하고 있었음을 알 수 있습니다.
1.DeepFM
DeepFm의 가장 큰 Contribution은 End-to-End로 모든 Order의 Interaction을 모델링할 수 있다는 것 입니다.
또한 DeepFM은 전문화된 feature engineering을 필요로하지 않습니다.
Model architecture

DeepFM은 FM Component와 Deep Component로 이루어져 있습니다.
각각 FM component는 Low-order를, Deep component는 High-order를 모델링하기 위해 사용됩니다.
두개의 Component는 서로 같은 Input과 Embedding을 공유합니다. 따라서 이는 Wide & deep 모델과의 차별점이라고 할 수있습니다.
또한 모든 파라미터는 아래의 예측 통해 동시에 학습이 진행됩니다(jointly training).
$$\hat{y} = sigmoid(y_{FM} + y_{DNN})$$
본 추천시스템의 목적은 CTR의 예측이기 때문에, \(\hat{y} \in (0,1)\) 이며 sigmoid 함수를 사용하고 있습니다.
각각의 Component에 대해 자세히 설명을 드리도록 하겠습니다.
1) FM Component

FM Component는 간단하게 Factorization Machine이라고 할 수 있습니다.
FM은 order-1 Interaction 뿐만 아니라, latent feature의 내적을 사용하여 order-2 Interaction 또한 모델링 할 수 있습니다.
기존의 FM과 거의 동일한 아래의 수식으로 FM Component는 계산이 가능합니다.
$$y_{FM} = <w,x> + \sum_{j_{1}=1}^{d}\sum_{j_{2}=j_{1}+1}^{d}<v_{j_{1}}, v_{j_{2}}> x_{j_{1}}x_{j_{2}}$$
$$w \in R^d, V_i \in R^k$$
\(w\)는 특성의 order-1 가중치를 의미합니다.
\(V_i\)는 i번째 feature의 latent vector를 의미하며, \(<V_i,V_j>\)는 특성 i, j 사이의 내적으로, order-2 가중치를 의미합니다.
기존의 FM구조와 거의 동일하기 때문에 자세한 내용은 아래의 리뷰를 참고 부탁드립니다.
[paper review][추천시스템] Factorization Machines
머신러닝과 데이터 마이닝에서 SVM은 가장 대중적으로 사용되는 예측기 중 하나입니다. SVM은 General Predictor로서 데이터의 형태에 크게 규제받지 않고 분류, 회귀 등 다양한 작업을 수행할 수 있다
supkoon.tistory.com
2) Deep Component

Deep Component는 feed-forward neural network로서 high-order Interaction을 학습하기 위한 구조입니다.
CTR 예측을 위한 데이터는 매우 Sparse한 categorical 특성과 Continuous한 특성이 혼재되어 있습니다.
따라서 Deep Component는 모든 특성의 저차원 임베딩을 신경망의 Input으로 활용합니다.

포인트는 두가지 입니다.
첫번째는 각기 다른 길이의 특성벡터를 동일한 크기의 임베딩 벡터로 표현한다는 것 입니다.
두번째는 FM Component에서 order-2 Interaction을 계산하기 위한 latent feature로 쓰인 \(V\)가 Deep Component에서는 input특성들을 임베딩 벡터로 만들기 위한 Embedding layer의 가중치역할을 한다는 것 입니다.
따라서 두가지 Component가 동일한 임베딩 층을 공유하고 있음을 다시한번 확인할 수 있습니다.
$$a^{(0)} = [e_1,e_2,...,e_m]$$
\(a^{(0)}\)는 임베딩 층의 output이며, \(e_i\)는 \(i\)번째 특성의 임베딩, m은 특성의 수 입니다.
$$a^{(l+1)} = \sigma(W^{(l)}a^{(l)}+b^{(l)})$$
\(a^{(0)}\)는 심층 신경망의 input이 되며, \(ㅣ\)번째 층은 일반적인 신경망의 연산을 수행합니다.
$$y_{DNN} = \sigma(W^{|H|+1}a^{|H|}+b^{|H|+1})$$
\(H\)개의 hidden layer를 거친 Deep component의 output은 위와 같습니다.
Wide & deep과의 차별점은 역시 두개의 Component가 동일한 임베딩을 공유하는 것 입니다. 임베딩을 공유하는 것은 다음과 같은 이점을 가져옵니다.
1) raw feature로 부터 low-order와 high-order feature Interaction을 동시에 학습할 수 있습니다.
2) 별도의 전문적인 Feature engineering을 필요로 하지 않습니다.
Comparison with other Model
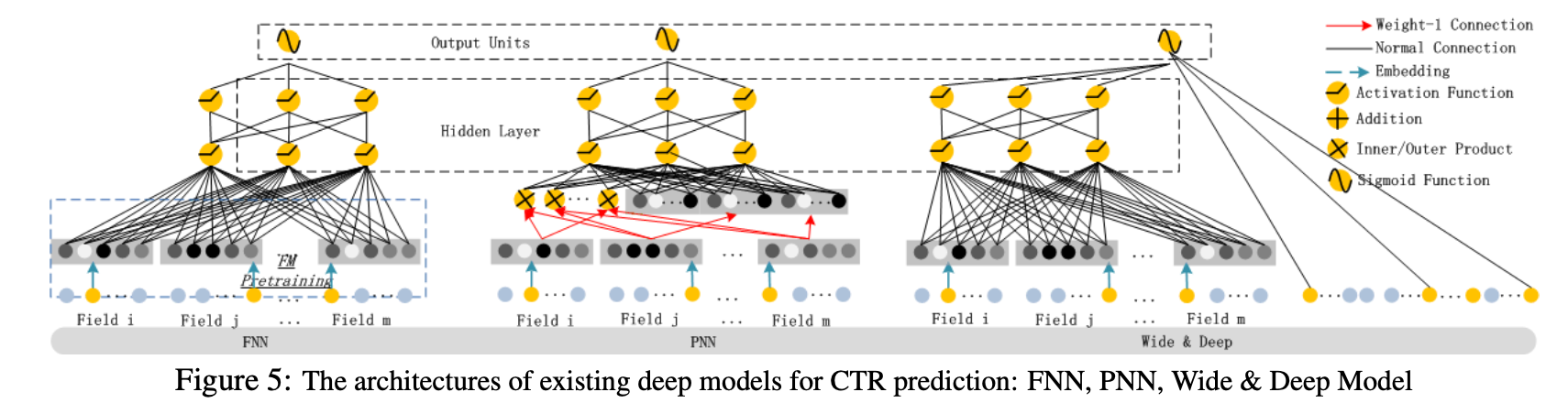

존재하는 CTR prediction 모델들과의 비교입니다.
Pre-training이 필요하지 않다는 점,
Low order와 High order Interaction이 모두 모델링 가능하다는 점,
추가적인 Feature Engineering을 필요로하지 않는다는 점에서 DeepFm이 비교 우위에 있음을 알 수 있습니다.
2. Results
검증은 Click records를 포함하고 있는 Criteo Dataset과 Company Dataset에서 이루어졌습니다.
비교를 위한 Metric에는 AUC와 LogLoss가 사용되었습니다.
result 1.

첫번째 실험은 Efficiency 비교입니다.
각각은 Linear 모델 대비 각 모델이 학습에 걸린 시간을 의미합니다.
DeepFM의 학습시간이 크게 우위에 있는 것은 아니지만, Pre-training을 필요로하지 않는다는 점이 주목할 만 합니다.
result 2.
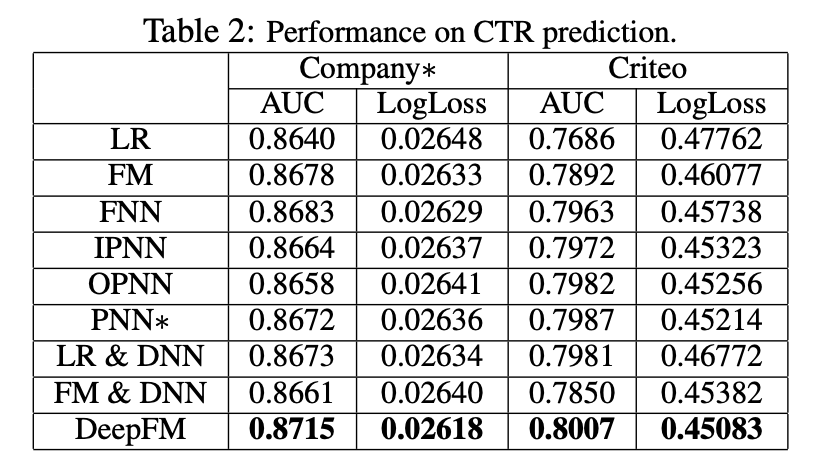
두번째는 Effectiveness 비교입니다.
우선 유일하게 Interaction을 고려하지 않는 LR모델이 나머지 Interaction을 고려하는 모델에 비해 성능이 떨어졌음을 확인할 수 있습니다. 따라서 Interaction의 고려가 CTR 예측에 긍정적인 영향을 준다는 것을 알 수 있습니다.
또한 High-order를 고려하는 모델들이 Low-order Interaction만을 고려하는 모델보다 성능이 좋았습니다.
그리고 최종적으로는 임베딩을 공유하는 DeepFM이 가장 좋은 CTR 예측 성능을 보였음을 알 수 있습니다.
3.구현
DeepFm에 대한 구현을 Movielens dataset을 활용하여 진행해 보았습니다.
CTR을 예측하는것이 더 적절하지만, 유사하게 평점 0~3.5 --> 0 , 4.0~5.0--> 1로 예측하는 binary classification을 진행하였습니다.
공부를 위한 목적이 크기 때문에, 논문의 모델을 구현하는데에 초점을 맞추었습니다. 양해 부탁드립니다.
GitHub - supkoon/deep_fm
Contribute to supkoon/deep_fm development by creating an account on GitHub.
github.com
마무리
DeepFM은 deep component와 FM component를 결합한 추천시스템입니다. DeepFM은 크게 세가지 장점이 존재하였습니다.
첫번째로는 Deep, FM Component를 통해 High-order Interaction과 Low-order Interaction을 모두 모델링 할 수 있다는 것 입니다.
두번째로는 두개의 Component 사이에 임베딩을 공유하여 부가적인 Featrue engineering을 필요로 하지 않는다는 것 입니다.
마지막은 DeepFM이 Pre-training을 필요로 하지 않는 다는 것 입니다.
기존의 모델들의 장점들을 잘 취합하여 효율적이며 효과적인 모델을 잘 개발한 것 같습니다.
특히 동일한 임베딩을 활용하여 다른 역할로 각각의 Component에서 활용한다는 아이디어가 좋았던 것 같습니다.