머신러닝과 데이터 마이닝에서 SVM은 가장 대중적으로 사용되는 예측기 중 하나입니다.
SVM은 General Predictor로서 데이터의 형태에 크게 규제받지 않고 분류, 회귀 등 다양한 작업을 수행할 수 있다는 장점이 존재합니다.
추천시스템은 대부분의 경우 User x Item으로 구성된 평점 행렬(rating matrix)을 채워나가는 Matrix Completion과 같습니다.
하지만 모든 유저가 모든 아이템을 평가하지 않는 이상 Sparse한 환경이 자주 발생하게 됩니다.
아쉽게도 추천시스템에 있어서 SVM은 대부분의 경우 좋은 선택이 되지 못합니다.
매우 Sparse한 환경에서는 복잡한 커널트릭이 잘 작동하지 않기 때문입니다.
2010년부터 현재까지, 추천시스템을 대표하는 알고리즘 중 하나는 협업 필터링의 일종인 Latent Factor model 입니다.
Matrix Factorization은 가장 대중적인 Latent Factor model로서, SVD(singular value decomposition)와 유사하게 유저와 아이템을 f차원의 잠재 공간(latent factor space)으로 매핑합니다.
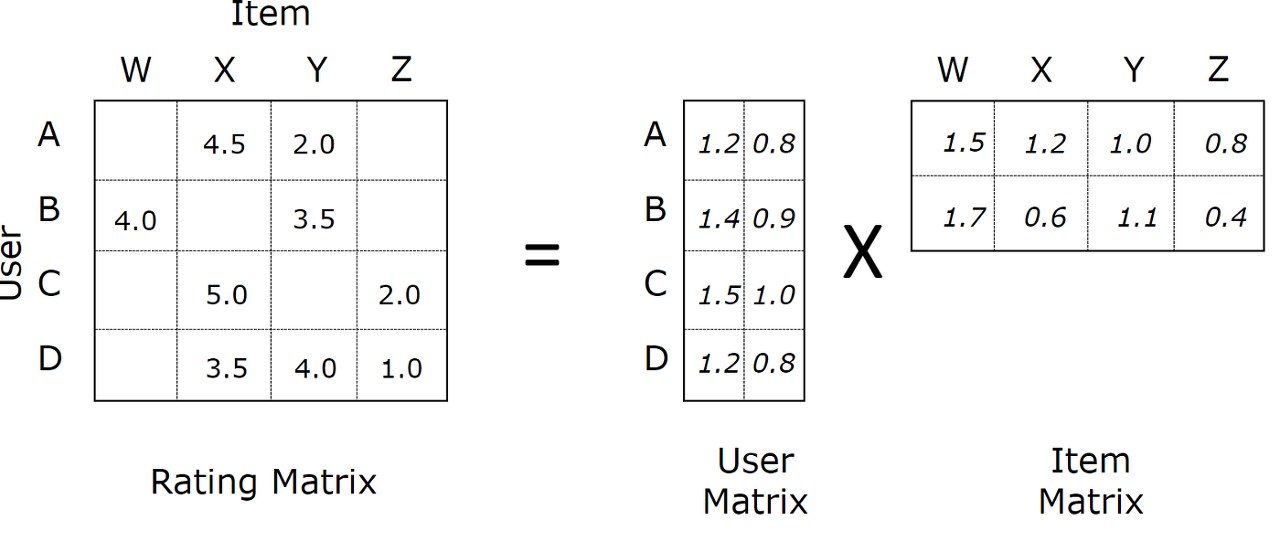
Matrix Factorization에서 Latent Factor는 User, Item 사이에 존재하는 패턴을 통해 찾을 수 있으며, f개의 latent factor로 표현된 user, item vector \(p_u,q_i\)의 내적으로 둘 사이의 상호관계 \(\hat{r_{ui}}\)를 간단히 구할 수 있습니다.
$$\hat{r_{ui}} = q^{T}_i p_u$$
추천시스템을 위한 Matrix Factorization의 자세한 설명은 아래의 리뷰를 참고 부탁드립니다.
[paper review][추천시스템]Matrix Factorization Techniques for recommender systems
Recommender System 정보가 넘쳐나는 현 시대에서 추천 시스템은 전자 상거래, 온라인 뉴스 및 소셜 미디어 사이트를 포함한 많은 온라인 서비스에 널리 채택되어 기호에 맞는 상품을 제공하고 있습
supkoon.tistory.com
하지만 Matrix Factorization은 SVM과 반대로 일반적인 데이터에 바로 적용할 수 없으며, 대부분의 경우 Task specific한 Model이라는 단점이 존재합니다.
본 논문은 2010년 발표된 논문으로 추천시스템을 위한 General predictor인 Factorization Machine(FM)을 소개하고 있습니다.
FM은 SVM과 Matrix Factorization의 장점을 함께 가지고 있는 모델입니다.
FM(Factorization Machines)은 다음과 같은 장점이 있습니다.
1) Sparse data : SVM으로 학습하기 어려운 Sparse 환경에서도 파라미터를 추정 가능합니다.
2) Linear Complexity : 선형복잡도를 가지고 있습니다. SVM과 같은 쌍대문제를 풀지 않아도 됩니다.
3) General Predictor : General Predictor로서 어떠한 실수 벡터를 사용하더라도 잘 작동합니다.
1.Factorization Machines
Factorization Machine이라는 이름 때문에 FM을 MF와 혼동하시는 분들이 계실 것 같습니다.
두 모델은 모두 기본적으로 평점과 같은 상호관계를 예측한다는 공통점이 존재합니다.
하지만 엄밀하게 따지면 FM과 MF은 서로 다르며, 오히려 FM은 Polynomial Regression에 가깝다고 할 수 있습니다.
Input representation
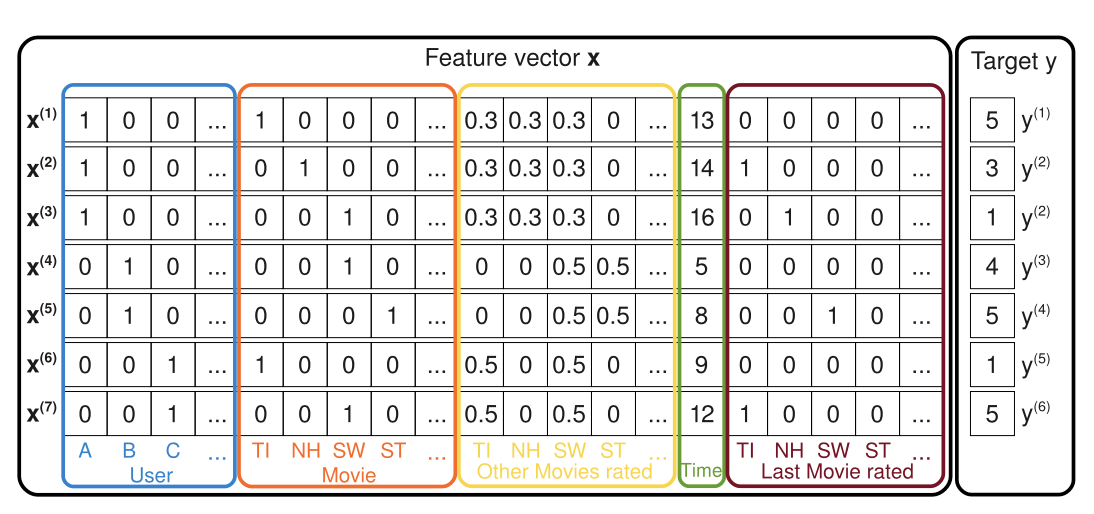
우선 FM은 매우 Sparse한 feature vector X를 다룹니다.
Matrix Factorization이 user, item, rating 만을 사용하는 것과는 다르게, FM은 위의 그림과 같이 다양한 Feature를 concatenate하여 하나의 feature vector로 사용합니다.
따라서 어떠한 implicit 특성이라도 실수 형태로 하나의 특성벡터 안에 추가할 수 있습니다.
FM은 각각의 user, item과 같은 Categorical feature는 One-hot 형태로 표현하여 x에 추가됩니다.
따라서 x는 일반적인 경우 매우 Sparse한 벡터가 됩니다.
이는 user, item을 Latent factor를 사용하여 f 차원 벡터로 나타내는 Matrix Factorization과 대조적입니다.
유저, 아이템을 포함한 다양한 특성이 하나의 벡터안에 공존하고 있다는 점이 SVM과 같은 일반적인 머신러닝 알고리즘과 유사합니다.
그림의 예시에서는 '유저가 평가한 다른 영화 정보', '시간', '최근에 평가한 영화'와 같은 특성을 추가한 것을 확인할 수 있습니다.
Factorization Machine Model
FM은 SVM의 선형커널(polynomial kernel)과 같이 모든 변수간의 상관관계를 모델링하는 형태를 가지고 있습니다.
하지만, SVM이 Dense Parametrization을 사용하는 것과 달리 FM은 factorized parametrization 방법을 사용합니다.
각각의 변수를 f 차원의 latent Factor로 매핑하여, 변수간의 상관관계를 Matrix Factorization과 같이 Latent Factor의 내적으로 모델링하는 것 입니다.
다음의 식은 2개 특성 사이의 관계를 고려하는 2-way(d=2) Factorization machine 입니다.
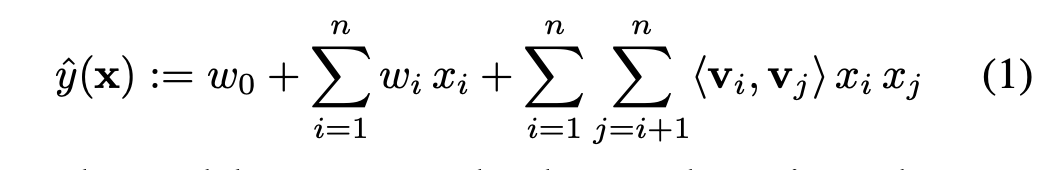
\(w_0\)는 \(\mathbb{R}\)차원의 Global bias를,
\(w_i\)는 i번째 개별 특성에 대한 가중치를,
\(<v_i,v_j>\)는 f개 latent factor로 표현된 변수간의 2-way Interaction을 계산하는 내적을 의미합니다.
만약 n개의 example에 대한 m개의 특성이 존재한다면, m개의 특성은 각각 f 차원의 벡터로 표현되어 서로 내적이 가능합니다.
이 때, 혼동되기 쉬운부분은 k 명의 User를 표현하는 k개의 one-hot 벡터 또한 k개 모두 따로 f 차원으로 매핑이 된다는 사실입니다.
예시)
Interaction 계산 시,
x : [유저 6차원 + 아이템 7 차원 + 다른 특성 n차원] ----factorized parametrization ----> x : [(6 + 7 + n) x f 차원]
루헨진 : [0,0,0,1,0,0] --> [ [f 차원] [f 차원] [f 차원] [f 차원] [f 차원] [f 차원] ]
야구공 : [0,0,1,0,0,0,0] --> [ [f 차원] [f 차원] [f 차원] [f 차원] [f 차원] [f 차원] [f 차원] ]
Feature vector x : [루헨진, 야구공, ..다른 특성들] -->
[ [f 차원] [f 차원] [f 차원] [f 차원] [f 차원] [f 차원] [f 차원] [f 차원] [f 차원] [f 차원] [f 차원] [f 차원] [f 차원] ..... ]
언뜻 보면 FM은 다항회귀와 매우 흡사하게 생각됩니다.
하지만, coefficient 대신 특성마다 latent space로의 매핑을 진행하고, latent space에서의 내적을 계산한다는 것이 FM의 가장 큰 특징입니다.(factorized parametrization)
$$<v_i,v_j> := \sum_{f=1}^k v_{i,f} \cdot v_{j,f}$$
또한 MF와의 차이점은 MF가 user, item의 상관관계 \(W_{user} \times W_{item}\) 만을 고려한다면,
FM은 각 특성의 1차 상관관계 \(W_i \times x_i\)와, 2차 상관관계 \(<v_i,\,v_j> x_ix_j\)를 모두 고려한다는 점 입니다.
FM은 예시의 2-way의 경우에도 모든 Interaction을 계산할 수 있으며,
Pairwise feature interaction을 고려하기 때문에 Sparse한 환경에 매우 적합한 모델입니다.
Expressiveness
latent space의 차원 f가 충분히 크다면 Positive definite matrix \(W\)에 대해 \(W=V \cdot V^T\)를 만족하는 \(V\)는 항상 존재합니다.
이것은 충분한 크기의 f 가 선택되었을 때, FM모델이 어떠한 Interaction Matrix \(W\)도 표현할 수 있음을 말합니다.
그럼에도 불구하고, 일반적으로 모든 복잡한 Interaction을 계산하기에는 데이터가 부족하기 때문에, 작은 k를 선택하여 Sparse 상황에서의 일반화 성능을 높히는 선택을 한다고 합니다.
Parameter Estimation Under Sparsity
일반적으로 Sparse한 환경에서는 변수들 간의 Interaction을 직접적, 독립적으로 추정하기 위한 충분한 데이터가 없는 경우가 많습니다.
FM은 Sparse한 경우에도, 변수 사이의 Interaction을 추정할 수 있습니다.
다시 말하면, 하나의 Interaction에 연관된 데이터가 다른 Interaction을 추정하는데 도움을 준다는 것 입니다.
예를 들어 유저 A의 아이템 B에 대한 선호도를 모른다면,
유저 A 혹은 아이템 B에 관한 다른 Interaction 들을 고려하여 삼단논법과 같이 이를 계산할 수 있게 됩니다.
Computation
FM의 가장 큰 장점 중 하나는 Linear Complexity를 가지고 있다는 것 입니다.
2-way Interaction만 고려하여도 \(O(kn^2)\)의 Complexity를 가질 것이라는 예상과 다르게,
아래의 식을 따라가면 FM이 n-way 환경에서도 Linear Complexity \(O(kn)\)를 갖는 다는 것을 알 수 있습니다.

Training
FM은 Linear complexity를 가지고 있습니다.
따라서 SGD를 사용하는 최적화 과정에서 FM의 파라미터 \(w_0,w_i,v_{i,f}\)는 효율적으로 학습이 가능합니다.
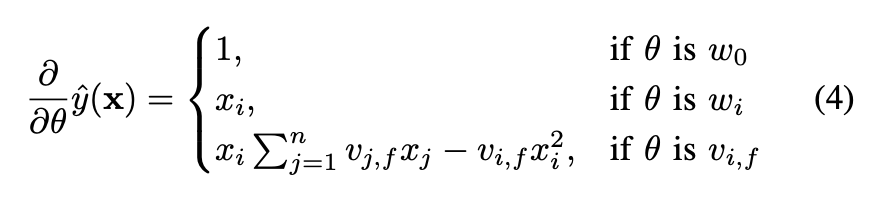
먼저, \( \sum_{j=1}^n v_{j, f} x_j\) 는 \(i\)에 독립적이기 때문에 먼저 계산이 가능합니다.
따라서 각각의 파라미터에 대한 그레디언트는 상수시간인 \(O(1)\)안에 계산이 가능해집니다.
결과적으로 모든 파라미터에 대한 업데이트가 \(O(kn)\)안에 이루어지기 때문에 계산 효율적인 측면에서도 FM은 더욱 큰 메리트를 갖고 있습니다.
d-way Factorization Machine
FM은 d-way로 일반화가 가능합니다.
말씀드린대로, d-way의 경우에도 선형 시간의 계산 복잡도를 가지고 있습니다.
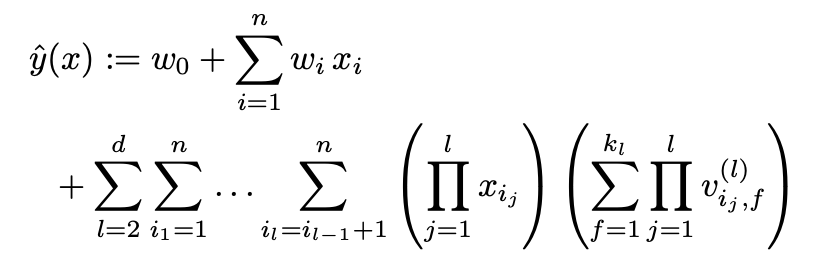
2.results
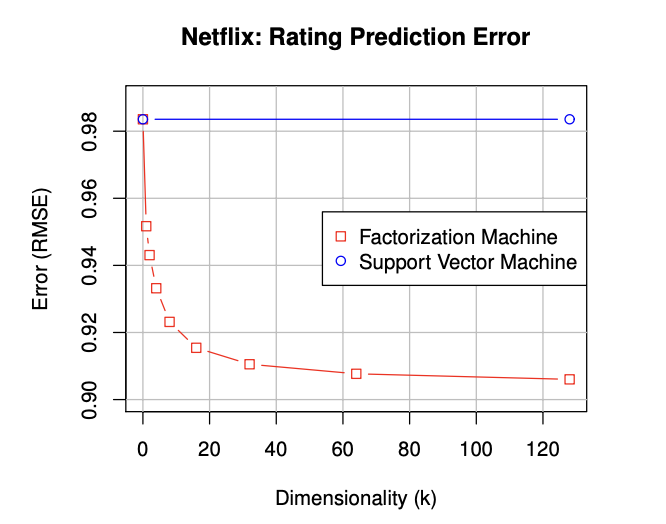
result 1.
첫번째 실험은 SVM과의 비교입니다.
매우 sparse한 Netflix 데이터셋을 사용하여 차원에 따른 성능을 비교하였습니다.
그 결과 SVM은 Sparse한 환경에서 학습에 실패하였으며, FM은 차원 증가에 따른 학습이 잘 진행되었음을 확인할 수 있습니다.
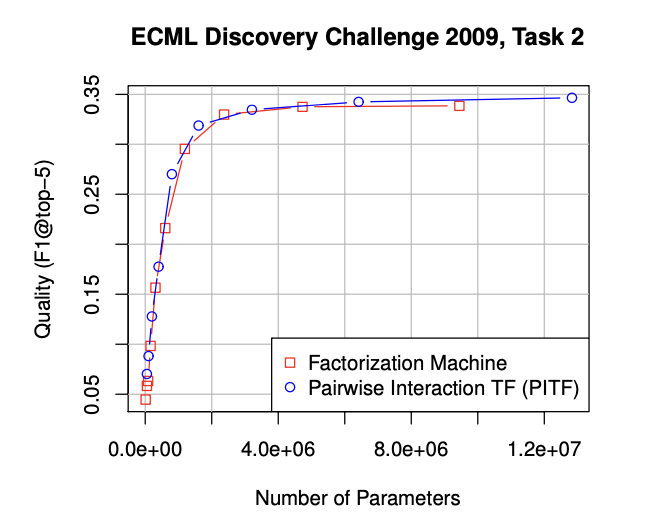
result 2.
당시 SOTA 모델인 PITF 모델과의 비교입니다.
파라미터 수에 따른 F1 score 성능이 거의 비슷함을 알 수 있는데,
PITF는 Task Specific 하지만, FM은 General predictor라는 점에서 FM의 우수성을 알 수 있습니다.
3. 구현
논문을 참고하여 Factorization Machine에 대한 구현을 진행하였습니다.
Movielens 데이터셋을 활용하였으며, 논문의 알고리즘을 정확히 구현하는데에 초점을 맞추었습니다. 이 점 양해 부탁드립니다.
supkoon/factorization_machine_tf
Contribute to supkoon/factorization_machine_tf development by creating an account on GitHub.
github.com
마무리
FM은 추천시스템의 한가지 모델로서 SVM과 Matrix Factorization의 장점을 모두 가지고 있습니다.
우선 SVM과 같은 general predictor로서 모든 실수 특성에 대해 자유롭게 적용 가능합니다.
FM은 Factorized Interaction을 활용하여 feature vector의 모든 가능한 Interaction을 모델링 하기 때문에, sparse한 환경에서도 Interaction을 학습할 수 있으며, 결측치에 대해서도 일반화된 예측을 보여줍니다.
또한 계산 효율적 측면에서도 Linear Complexity를 보여주었는데, 이는 2-way FM 뿐만 아니라 일반화된 n-way FM에서도 동일하게 적용되었습니다.
Matrix Factorization과 이름은 비슷하지만, Implicit, Explicit 특성을 쉽게 추가하여 추천할 수 있다는 점이 큰 장점인 것 같습니다.
또한 선형복잡도로 유도되는 과정이 매우 깔끔하게 느껴졌습니다. 다음 시간에는 FM에 신경망을 적용한 DeepFm과 wide&deep에 대해 리뷰해보도록 하겠습니다. 감사합니다.