1. Question & Answering
Question Answering(QA) task는 말그대로 질문에 대한 대답을 생성하는 NLP task 입니다.
QA는 Text에 대한 이해와 사실(fact)에 대한 추론 능력을 모델에게 요구하기 하기 때문에 매우 복잡한 작업 중 하나로 손꼽힙니다.
하지만 머신러닝 알고리즘을 사용하는 이유 자체가 특정 문제(Q)에 대한 해결(A)이라는 관점에서 봤을 때, QA Task는 사실 매우 General한 문제를 다루고 있습니다.
이는 NLP Task에도 동일하게 적용되며, 아래의 예시와 같이 대부분의 NLP Task는 QA Task로 general하게 표현될 수 있습니다.

2. Dynamic Memory Networks
2016년 발표된 본 논문은 general Question Answering을 위한 신경망 기반의 모델인 Dynamic Memory Network(DMN)를 소개하고 있습니다.
DMN은 (input,question,answer) triplet을 input으로 받아 학습하며, 질문에 대한 추론을 통해 tagging, classification, seq2seq, QA 등 다양한 NLP 문제를 해결할 수 있는 General한 모델입니다.
Model architecture
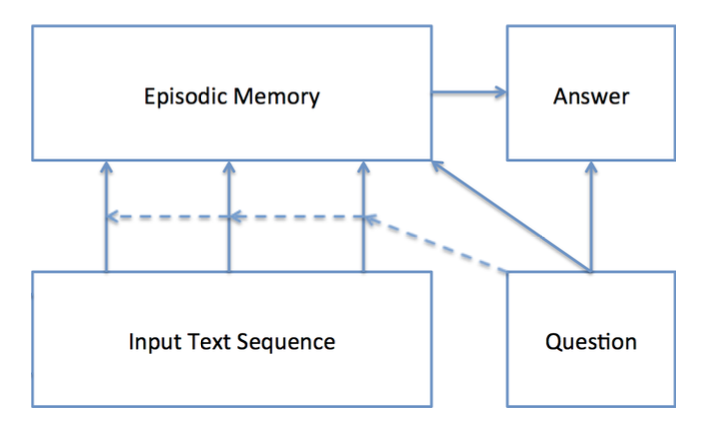
DMN은 각기 다른 역할을 하는 네가지의 모듈로 구성되어 있어, Input과 Question을 입체적으로 고려한 Answering이 가능합니다.
각 모듈은 Input module, Question module, Episodic memory module, Answer module로 이에 대한 간단한 설명을 먼저 드리도록 하겠습니다.
1)Input Module
간단한 문장부터 긴 글과 같은 raw text input을 distributed vector representation으로 인코딩 하는 역할을 수행합니다.
2)Question Module
Input Module과 동일하게, question을 distributed vector representation으로 인코딩 하는 역할을 수행합니다.
이어지는 Episodic Memory Module의 initial state로 사용됩니다.
3)Episodic Memory Module
Question이 Input representation의 어떤 부분에 집중하여야 하는지를 Attention을 통해 반복적으로 계산합니다.
각 반복은 이전 반복의 memory vector를 고려하여 새로운 memory vector를 생성합니다.
반복을 통하여 이전에 고려하지 못한 새로운 정보를 추가적으로 찾아낼 수 있습니다.
4)Answer Module
Memory Module로 부터 받은 마지막 memory vector를 사용하여 답변을 생성합니다.
DMN은 위와 같이 네가지 모듈의 역할을 통하여 Question answering task를 수행할 수 있습니다.
이제 그림과 수식을 통하여 각각의 모듈에 대한 자세한 설명을 드리도록 하겠습니다.
Input Module

Input Module은 단어 \(w_{ 1 },...., w_{ { T }_{ I } }\)로 이루어진 길이 \(T_I\)의 Input sequence 에 대한 인코딩을 진행합니다.
인코딩은 다음과 같이 RNN Layer의 연산을 통해 구해질 수 있습니다. \(L\)은 embedding matrix를 의미합니다.
$$h_{ t }=RNN(L[w_{ t }],h_{ t-1 })$$
본 논문에서는 RNN layer로 GRU를 선택하였습니다. 잘 아시다시피 GRU는 기본적인 RNN에 비해 vanishing gradient problem에 있어 강한 모습을 보여줍니다. 또한 GRU는 더 복잡한 구조의 LSTM보다 낮은 계산복잡도로 비슷한 성능을 보였다고 합니다.
$$z_{ t }=\sigma ({ W }^{ (z) }x_{ t }+{ U }^{ (z) }h_{ t-1 }+b^{ (z) })$$
$$r_{ t }=\sigma ({ W }^{ (r) }x_{ t }+{ U }^{ (r) }h_{ t-1 }+b^{ (r) })$$
$$\tilde { h } _{ t }=tanh({ W }x_{ t }+r_{ t }\circ { U }h_{ t-1 }+b^{ (h) })$$
$$h_{ t }=z_{ t }\circ h_{ t-1 }+(1-z_{ t })\circ \tilde { h } _{ t }$$
$$h_{ t }=GRU(L[w_{ t }],h_{ t-1 })$$
Input Module의 입력은 다음과 같이 두가지 경우가 존재할수 있습니다.
1)Input sequence가 하나의 문장일 경우
Input sequence가 하나의 문장일 경우에는 RNN의 hidden state들이 Input Module의 output representation이 됩니다.
Output representation을 Fact representation \(c\)라고 한다면,
하나의 문장에 대한 Fact representation \(c\)의 길이 \(T_c\)는 문장의 단어 수 \(T_I\)와 같을 것 입니다.
2)Input sequence가 두개 이상의 문장일 경우
Input sequence가 두개 이상의 문장으로 구성되어 있을 경우, 입력단에서 각 문장을 EOS 토큰으로 구분하여 concatenate 합니다.
이 때, output representation은 각 EOS토큰에 대한 hidden state가 됩니다.
따라서, Fact representation c의 길이 \(T_c\)는 문장의 수(=EOS 토큰 수)가 될 것입니다.
Question Module

Input sequence와 유사하게 question 또한 단어의 시퀀스로 구성되어 있습니다.
Question module또한 GRU를 사용하여 길이 \(T_Q\)의 question sequence \(q =\{w_{ 1 },...., w_{ { T }_{ Q }} \} \) 를 인코딩 합니다.
$$q_{ t }=GRU(L[{ w }_{ t }^{ Q }],q_{ t-1 })$$
동일하게 \(L\)은 embedding matrix이며, 이는 Input Module과 공유됩니다.
하지만 마지막 hiiden state인 \(q=q_{T_Q}\) 만을 output representation으로 사용한다는 차이점이 존재합니다.
Episodic Memory Module

Episodic Memory module은 fact representation \(c\)와 question representation \(q\)를 반영한 episodic memory를 반복적으로 계산하여 Answer module로 전달하는 역할을 합니다.
episodic memory를 구하기 위해 가장 먼저 필요한 것은 각 fact \(c_t\)에 대한 episode \(e_{t}^i\)입니다.
episode \(e_t^i\)는 Fact \(c_t\)와 Question \(q\), 그리고 이전 episodic memory \(m^{i-1}\) 사이의 attention을 통해 계산됩니다.
\(G(c_t,m^{i-1},q)\)는 attention 계산을 위해 사용되는 scoring function입니다.
간단히 \(G\)는 feature set \(z(c,m,q)\)를 입력으로 받아 스칼라 형태의 attention score를 출력합니다.
본 논문에서는 다음과 같이 다양한 유사도를 반영할 수 있는 feature set \(z(c,m,q)\)이 사용되었습니다.
$$z(c,m,q)=[c,m,q,c\circ q,c\circ m,\left| c-q \right| ,\left| c-m \right| ,{ c }^{ T }{ W }^{ (b) }q,{ c }^{ T }{ W }^{ (b) }m]$$
또한 scoring function \(G\)으로는 학습이 가능한 간단한 형태의 2-layer feed-forward neural network가 사용되었습니다.
$$G(c,m,q)=\sigma ({ W }^{ (2) }tanh({ W }^{ (1) }z(c,m,q)+b^{ (1) })+b^{ (2) })$$
본 논문에서는 attention을 gate function으로 사용하였습니다.
먼저, i 번째 iteration의 fact \(c_t\)에 대한 gate \(g_t^i\)는 계산된 Attention인 \(G(c_{ t },m^{ i-1 },q)\)가 됩니다.
$$ { g }_{ t }^{ i }=G(c_{ t },m^{ i-1 },q)$$
gate function인 \(g\)는 GRU의 일반적인 gate function과 같이 적용되어 episode를 업데이트 합니다.
$${ h }_{ t }^{ i }={ g }_{ t }^{ i }GRU(c_{ t },{ h }_{ t }^{ i-1 })+(1-{ g }_{ t }^{ i }){ h }_{ t }^{ i-1 }$$
(\(h_t^i\)는 GRU의 hidden state를 의미하기 때문에 그림의 \(e_t^i\)로 생각하셔도 될 것 같습니다.)
$$e^{ i }={ h }_{ { T }_{ c } }^{ i }$$
마지막 fact \(c_{T_c}\)에 대한 GRU의 hidden state \(h_{T_c}^i\)인 episode \(e^i\)는 이전 Episodic memory \(m^{i-1}\)와 함께 GRU로 입력되어 새로운 Episodic memory \(m^{i}\)를 생성하게 됩니다.
$${m}^{i}=GRU({e}^{i},{m}^{i-1})$$
GRU의 initial state \(m^0\)로는 question representation \(q\)이 사용됩니다.
최종적으로 새로운 Episodic memory \(m^i\)는 Answer module로 전달됩니다.
Need for Multiple Episodes
반복을 통하여 다양한 에피소드를 계산하는 것은 모델이 매 반복에서 새로운 Fact에 집중할 수 있도록 합니다.

그림의 "where is the fooball?"이라는 질문을 예시로 들어 설명드리도록 하겠습니다.
먼저 첫번 째 Iteration의 Attention은 질문인 "where is the fooball?"과 \(S_7\) "john put down the fooball"의 fooball에 집중되어 이에 대한 정보가 \(m^1\)에 저장됩니다.
두번째 Iteration의 Attention은 \(m^1\)로 부터 \(S_7\) "john put down the fooball"에 대한 정보를 얻습니다.
따라서 \(S_6\)과의 Attention이 강해져 "john went to the hallway"로 부터 John이 어디에 있는지 파악할 수 있게 합니다.
따라서 두번의 반복을 통해 "John이 hallway에 있으며, fooball을 가져다 놓았다" 라는 구체적인 답변을 완성시킬 수 있게 됩니다.
Criteria for Stopping
Memory 업데이트를 위한 반복은 다음과 같은 경우에 종료됩니다.
1) 명확한 label이 존재하는 경우
EOP(end-of-passes) 토큰을 Input에 추가하여 gate function에 이 토큰이 선택될때까지 Iteration을 반복합니다.
2) 명확한 label이 존재하지 않는 경우
최대 반복 횟수를 정합니다.
Answer Module
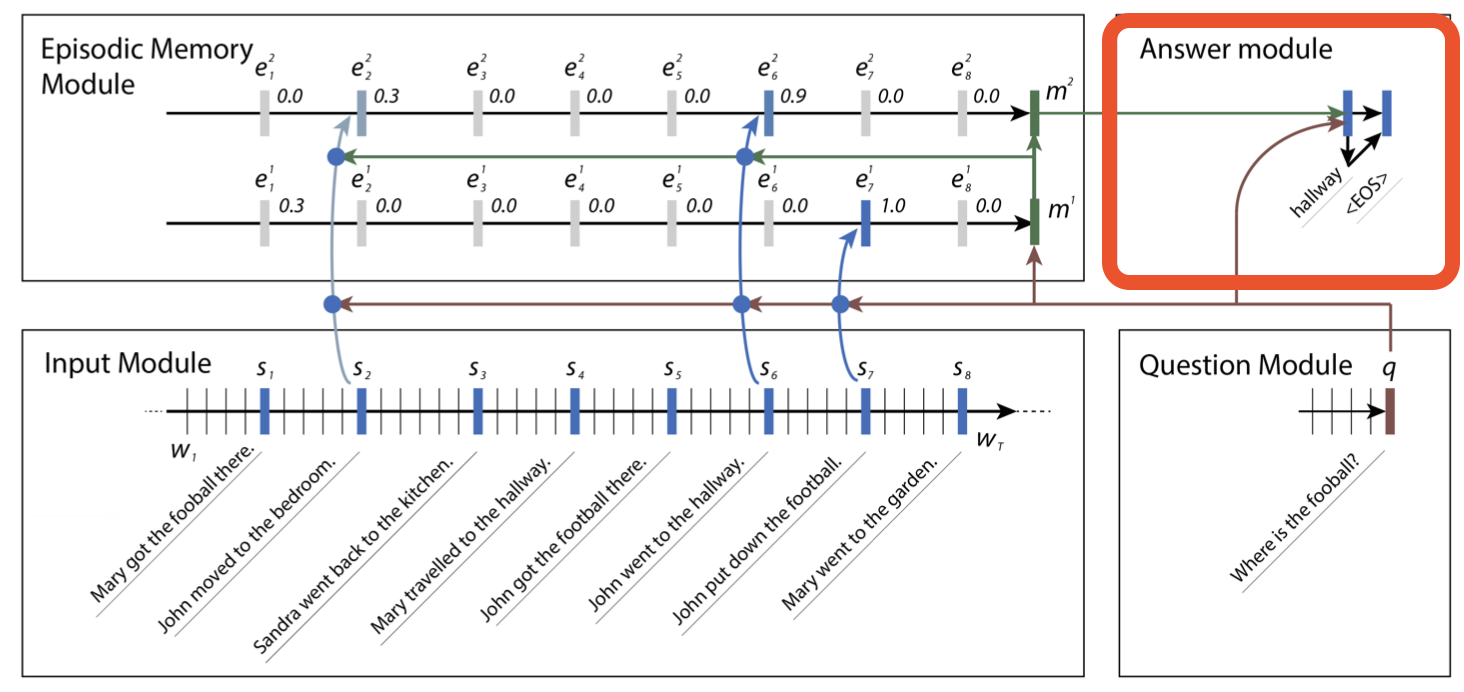
Answer Module은 Episodic Memory를 전달받아 최종적으로 질문에 대한 답변을 생성하는 역할을 합니다.
Task의 종류에 따라서 모든 Episodic Memory에 대한 답변을 생성하는 경우가 존재하며, 마지막 Episodic Memory만을 사용하여 한번의 생성과정을 거치는 경우 또한 존재합니다.
생성과정에서는 역시 GRU가 사용됩니다. 또한 마지막 메모리인 \(a_0 = m^{T_M}\)는 GRU의 initial state가 됩니다.
$$a_{ t }=GRU([y_{ t-1 },q],a_{ t-1 })$$
먼저 모든 t step에서 이전 단계의 output \(y_{t-1}\)과 question representation을 concatenate하여 hidden state \(a_t\)를 계산합니다.
$$y_{ t }=softmax({ W }^{ (a) }a_{ t })$$
그리고 계산된 hidden state를 softmax함수에 통과시켜 t step의 output word \(y^t\)를 얻습니다.
Training
학습은 End-to-End로 진행됩니다.
손실함수는 일반적인 Classification 문제로 정의되어 정답 시퀀스 label과의 Cross-entropy loss를 최소화 하는 방향으로 진행됩니다.
loss function은 다음 두가지 경우에 따라 달라질 수 있습니다.
1) gate에 대한 정답이 존재하는 데이터셋
본 논문에서 사용한 bAbI 데이터셋의 경우에는 질문에 관련된 단어들이 labeling 되어 있습니다.
이렇게 gate에 대한 정답이 존재하는 경우에는 gate에 대한 Cross-entropy 또한 고려하여 손실함수를 정의합니다.
$$J = \alpha E_{CE}(Gates) + \beta E_{CE}(Answers)$$
\(E_{CE}\)는 Cross-entropy를 의미하며, \(\alpha\), \(\beta\)는 하이퍼 파라미터입니다.
gate가 충분히 학습되지 않은 학습 초기에는 \(\alpha=1\) \(\beta=0\)을 사용하며,
gate가 충분히 학습되면 \(\alpha=1\), \(\beta=1\)을 사용합니다.
2) gate에 대한 정답이 존재하지 않는 데이터셋
일반적인 데이터셋의 경우에는 질문과 관련된 단어를 labeling하지 않고 있습니다.
따라서 이러한 경우 생성된 답안과 정답에 대한 Cross-entropy만을 고려하여 손실함수를 정의합니다.
$$J =E_{CE}(Answers)$$
Optimizer로는 일반적인 Gradient Descent가 사용되었습니다.
3. Results
검증 과정은 QA, POS tagging, sentiment analysis와 같이 다양한 NLP Task에서 진행되었습니다.
result 1.
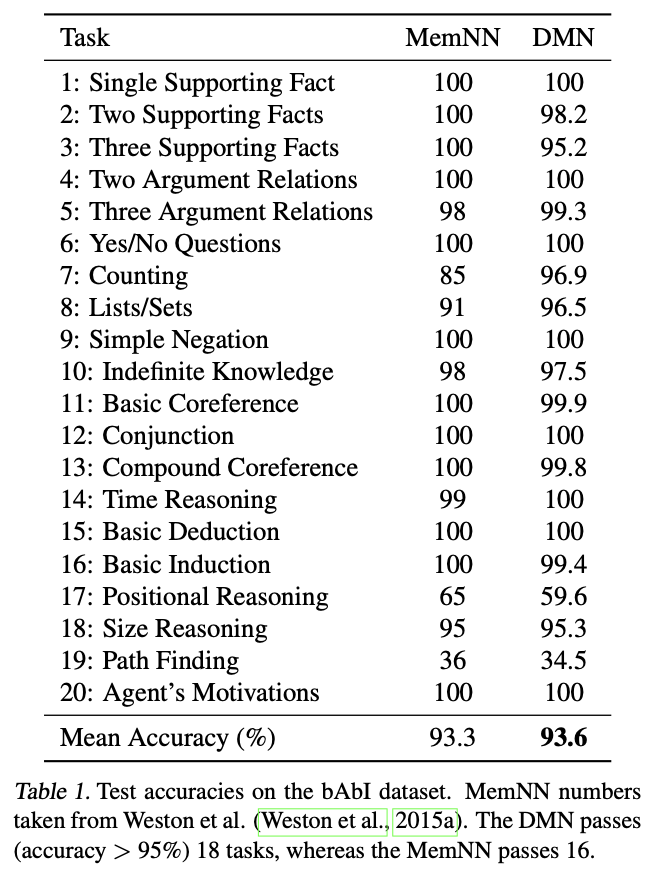
첫번째 실험은 QA Task에 대한 Accuracy 비교입니다.
검증 과정에는 20개의 Task를 포함하고 있는 Facebook bAbI 데이터셋이 사용되었습니다.
Facebook bAbI 데이터 셋은 사실확인과 추론능력에 대한 모델 성능을 테스트하기 위한 데이터셋들이 포함되어 있습니다.
여러개의 문장으로 이루어진 Task 2, 3을 제외하고는 제안하는 방법인 DMN이 상대적으로 더 좋은 성능을 보였음을 알 수 있습니다.
특히 복잡한 추론이 필요한 Task 7, 8의 경우 DMN이 반복적 사실 확인을 통하여 월등히 좋은 성능을 보였습니다.
result 2.

두번째 실험은 Classification의 일종인 Sentiment analysis 입니다.
실험은 Stanford Sentiment Treebank 데이터셋을 활용하여 진행되었습니다.
Positive/Negatve의 이진분류를 하는 경우와, very negative/ negative/ neutral/ positive/ very positive 총 5개의 label을 갖는 다중분류의 경우 모두에서 제안하는 모델인 DMN이 가장 우수한 성능을 보였습니다.
result 3.
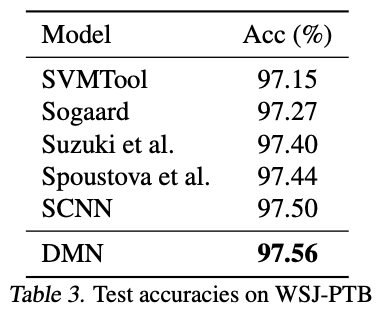
세번째 실험은 Sequence tagging의 일종인 POS tagging 입니다.
standard wall street journal 데이터셋을 활용하여 진행되었습니다.
DMN이 기존의 SOTA 모델보다도 좋은 성능을 보였음을 확인할 수 있습니다.
result 4.
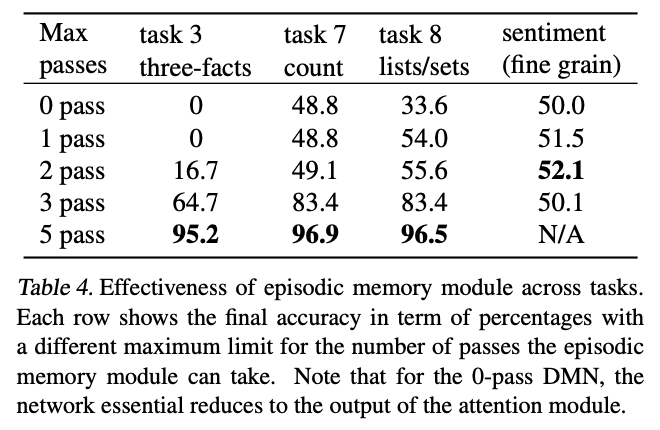
네번째 실험은 모델에서 가장 중요한 부분인 Episodic Memory Module에 대한 정량적 유효성 검증입니다.
Task 3, 7, 9 과 같은 어려운 추론을 요구하는 Task의 경우 반복(pass)이 큰 도움이 되었음을 알 수 있습니다.
반면에 Sentiment analysis와 같이 특정한 단어가 정답을 나타낼 가능성이 큰 Task의 경우, 반복이 진행됨에도 성능 향상이 이루어지지 않았습니다.
result 5.


다섯번째 실험은 Episodic Memory Module에 대한 정성적 유효성 검증입니다.
다양한 예시를 통하여 Memory Module이 매번 반복마다 새로운 정보를 학습하고 있다는 것을 확인할 수 있습니다.
Figure 4의 예시는 Iteration을 통해 sentiment를 나타내는 단어에 대한 Attention이 변화하며, 따라서 예측 또한 정확해질 수 있다는 사실을 보여주고 있습니다.
마무리
DMN(Dynamic Memory Networks)은 Episodic Memory의 반복적 계산을 통해 General한 QA Task를 해결할 수 있는 모델입니다.
다양한 문제를 해결할 수 있다는 장점과 더불어, 각기 다른 역할을 하는 4개의 Module로 구성되어 다양한 정보를 습득하고 활용할 수 있다는 장점이 존재합니다.
Iteration을 통한 fact retrieval의 효과를 정성적으로 시각화한 것이 직관적으로 잘 다가와 좋았습니다. 모델 구조에 대해서 조금만 더 자세하게 시각화 한 자료가 있었으면 조금 더 도움이 됐을 것 같아 아쉬웠던 것 같습니다. 하지만 Attention과 같은 방법론들을 먼저 공부한 덕분에 많이 헤매지 않고 끝까지 읽을 수 있었던 것 같습니다. 감사합니다.