CNN
CNN은 컴퓨터 비전 분야를 위해 개발되었으며, 대중적으로 사용되고 있는 가장 보편화된 이미지 처리 알고리즘입니다.
CNN은 가중치를 갖는 필터를 사용하기 때문에 개별 픽셀에 대한 가중치를 고려하지 않아도 됩니다.
따라서 CNN을 사용하는 모델은 파라미터를 효율적으로 사용하여 매우 큰 차원의 이미지를 처리할 수 있습니다.


CNN in NLP
CNN은 자연어 처리를 위해서도 효과적으로 사용되고 있습니다.
실제로 전통적인 일부 자연어처리 Task의 경우, CNN이 훌륭한 성능을 보인 사례들이 존재합니다.
대표적인 CNN의 적용분야는 자연어처리의 가장 주된 Task 중 하나인 Text Classifiction입니다.

앞서 리뷰하였던 "Convolutional Neural Networks for Sentence Classification" 에서는 Word2Vec로 임베딩된 단어(word)에 CNN을 적용하는 방법으로 Classification 작업을 성공적으로 수행할 수 있었습니다.
Word based ConvNet과 같이, 대부분의 NLP Task는 단어에 대한 임베딩을 가장 기본적인 입력으로 합니다. 단어 기반의 임베딩은 N-gram과 같은 방법을 사용하여 여전히 뛰어난 효과를 보이고 있습니다.
2016년에 발표된 본 논문은 문자(Character)단위의 CNN을 사용한 Text Classification 모델 Character-level ConvNet을 제안하고 있습니다.
1.Character-level ConvNet
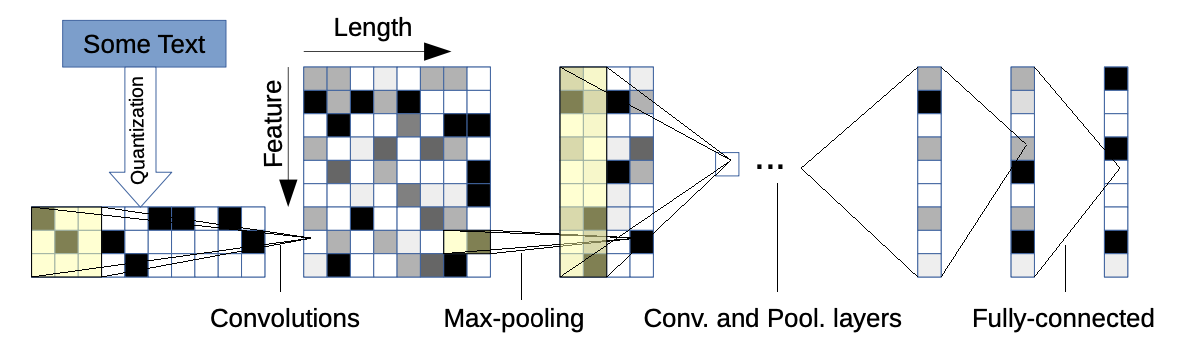
Input representation

우선 모델의 입력에 대해 먼저 설명드리도록 하겠습니다.
Character-level ConvNet이라는 이름에 맞게, 본 모델은 문자로 구성된 시퀀스를 입력으로 받습니다.
하나의 문자 시퀀스는 \(l_0\)의 길이를 갖는 고정길이 벡터입니다.
따라서 시퀀스의 길이가 \(l_0\)를 초과하는 문자에 대해서는 고려하지 않으며, 시퀀스가 \(l_0\)보다 짧아 미달되거나 존재하지 않는 문자에 대해서는 영벡터(Zero-vector)로 처리합니다.
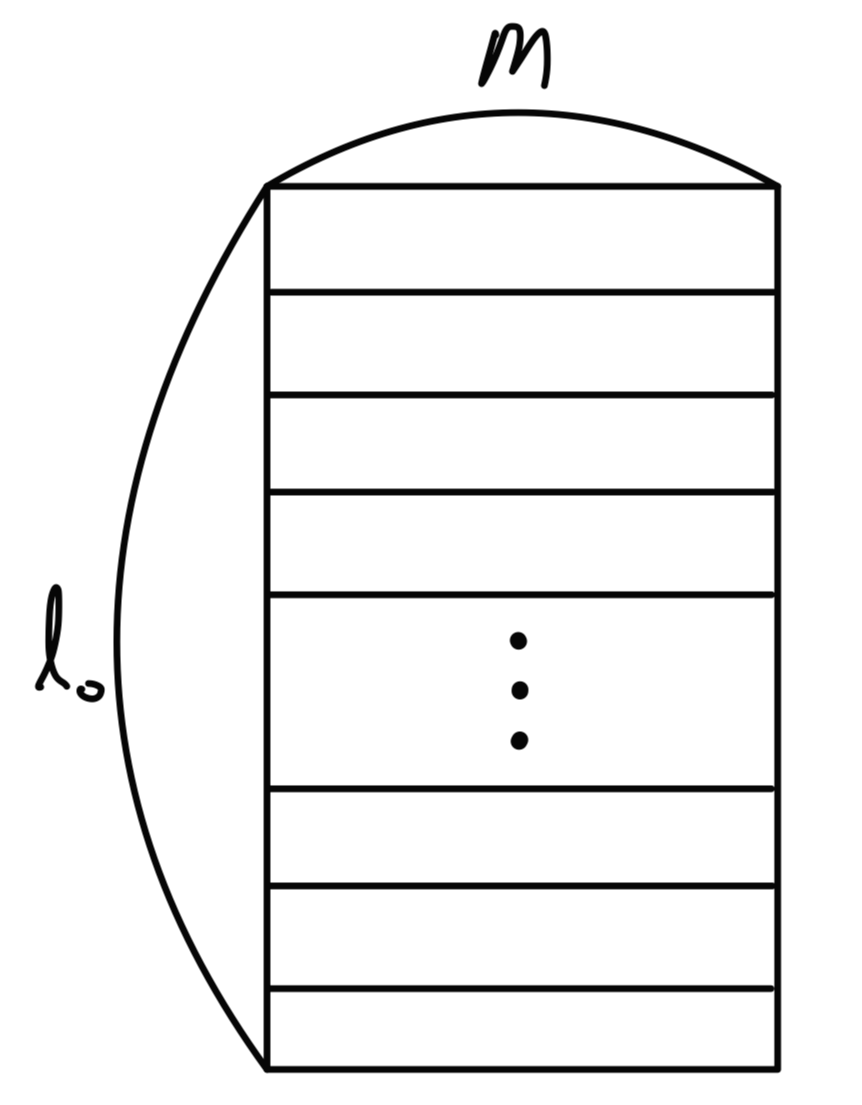
각각의 문자는 One-hot의 형태로 표현됩니다.
따라서 모델이 \(m\)개의 문자를 사용한다면 개별 문자는 \(m\)차원의 특성벡터로 표현될 것이며, 전체 시퀀스는 \(l_0\times m\) 차원의 행렬로 표현될 것입니다.
Character quantization
본 논문에서는 총 70개의 알파벳 문자를 사용하여 모델링하였습니다.\((m=70)\)
70개의 문자는 26개의 영어 문자, 10개의 숫자, 33개의 기타 문자, 그리고 1개의 space 문자를 포함하고 있습니다.

이는 대, 소문자의 구분을 따로 하지 않는 형태입니다. 저자들은 대, 소문자의 구분이 주는 영향에 대한 실험 또한 이후에 진행하였습니다
Data Augmentation using Thesaurus
Data augmentation은 모델의 일반화 성능을 끌어올릴 수 있는 효과적인 방법입니다.
하지만 이미지 데이터에 적용하는 augmentation 방법은 텍스트 데이터에 잘 맞지 않습니다.
가장 좋은 text 데이터의 augmentation 방법은 사실 인간이 직접 rephrasing를 하는 것 입니다. 하지만 이는 데이터의 크기가 증가할 수 록 비용부담이 크기 마련입니다.
따라서 일반적인 선택은 단어의 synonym(Thesaurus)을 활용하는 방법이 됩니다.
저자들은 기하분포 \(P[r] \sim p^r\)로부터 샘플링된 r개의 단어를 synonym으로 교체하였으며, 같은 기하분포 \(P[s] \sim q^s\)로 부터 샘플링된 s를 통해 synonym의 index를 결정하였습니다.
(기하분포를 통해 추출하였기 때문에, 자주 사용되는 의미와 거리가 멀수록 synonym으로 선택될 가능성이 적을 것이라는 직관적인 생각을 해볼 수 있습니다.)
ex) [아기,유아,소년,청년]일때, 아기 synonym으로 선택될 확률 : 유아 > 소년 > 청년
Model architecture

본 모델의 가장 핵심적인 부분은 temporal convolutional module 입니다.
temporal convolutional module은 시퀀스를 다룰 때 많이 사용하는 CNN의 일종입니다.
일반적으로 이미지 처리를 위해 수행되는 convolution 계산이 2개의 축을 따라 움직이는 것과는 다르게, 시퀀스를 다루기 위한 convolution은 시퀀스의 흐름에 따른 축으로만 이동하며 1-D convolution 계산을 수행합니다.
temporal convolutional \(h(y)\)는 다음과 같은 수식으로도 표현할 수 있습니다.
$$h(y)=\sum^k_{x=1}f(x)\cdot g(y\cdot d-x+c)$$
\(g(x)\)는 \(g(x) \in [1,l] \rightarrow \mathbb{R}\)인 input function을,
\(f(x)\)는 \(f(x) \in [1,k] \rightarrow \mathbb{R}\)인 kernel function을,
\(c\)는 \(c=k-d+1\)인 offset constant를 의미합니다.
따라서 1-d convolution인 \(h(y)\)의 output은 \(h(y) \in [1,\lfloor(l-k)/d\rfloor + 1]\rightarrow \mathbb{R}\)이 될 것입니다.
일반적인 CNN과 같이 temporal convolutional module 또한 이러한 kernel function들의 집합을 가중치로 갖습니다.
input \(g_i(x)\)에 대한 output \(h_j(y)\)의 계산을 위해 사용되는 가중치는 다음과 같이 표현가능합니다.
$$f_{ij}(x) (i=1,2,...,m\,\,\& j=1,2,...,n) $$
따라서 output \(h_j(y)\)는 \(g_i(x)\)와 \(f_{ij}\)사이의 convolution 연산을 통해 계산된다고 할 수 있습니다.

이어지는 temporal max-pooling 또한 1-D 버전의 max-pooling을 의미합니다.
따라서 마찬가지로 아래와 같이 temporal max-pooling 연산을 표현할 수 있습니다.
$$h(y)=\max^k_{x=1}g(y\cdot d-x+c)$$
\(g(x)\)는 \(g(x) \in [1,l] \rightarrow \mathbb{R}\)인 input function을 의미하며,
1d max-pooling function인 \(h(y)\)의 output은 \(h(y) \in [1,\lfloor(l-k)/d\rfloor + 1]\rightarrow \mathbb{R}\)이 될 것입니다.
pooling은 겹치지 않도록 stride를 유지하여 진행되었습니다.
max-pooling은 당시 모델들이 어려움을 겪었던 6-layer 이상의 ConvNet을 본 모델이 구성할 수 있도록 도움을 주었다고 합니다.
최종적으로 fully-connected layer의 classification을 위한 output node 수는 task에 맞게 설정됩니다.
제안하는 모델의 세부 구조는 다음과 같습니다.


비선형 활성함수로는 ReLU \(max\{0,x\}\)가 사용되었으며, SGD를 통해 학습이 진행되었습니다.
2.Results
Comparison models
비교를 위해 다음과 같은 전통적인 선형모델과 비 선형의 딥러닝모델이 사용되었습니다.
Traiditional methods
1)Bag of words , logistic regression
2)Bag of words + TFIDF , logistic regression
3)Bag of ngrams , logistic regression
4)Bag of ngrams +TFIDF, logistic regression
5)Bag of means(kmeans of Word2Vec), logistic regression
Deep learning methods
1)Word-based ConvNets
[자연어처리][paper review] Convolutional Neural Networks for Sentence Classification
CNN CNN은 컴퓨터 비전 분야를 위해 개발되었으며, 대중적으로 사용되고 있는 가장 보편화된 이미지 처리 알고리즘입니다. CNN은 가중치를 갖는 필터를 사용하기 때문에 개별 픽셀에 대한 가중치
supkoon.tistory.com
2)LSTM
Datasets
CNN은 학습을 위해 보통 많은 양의 데이터를 필요로 합니다.
하지만 당시의 텍스트 데이터의 크기가 크지 않았는지 새로 대규모 데이터를 생성하여 사용하였다고 합니다.
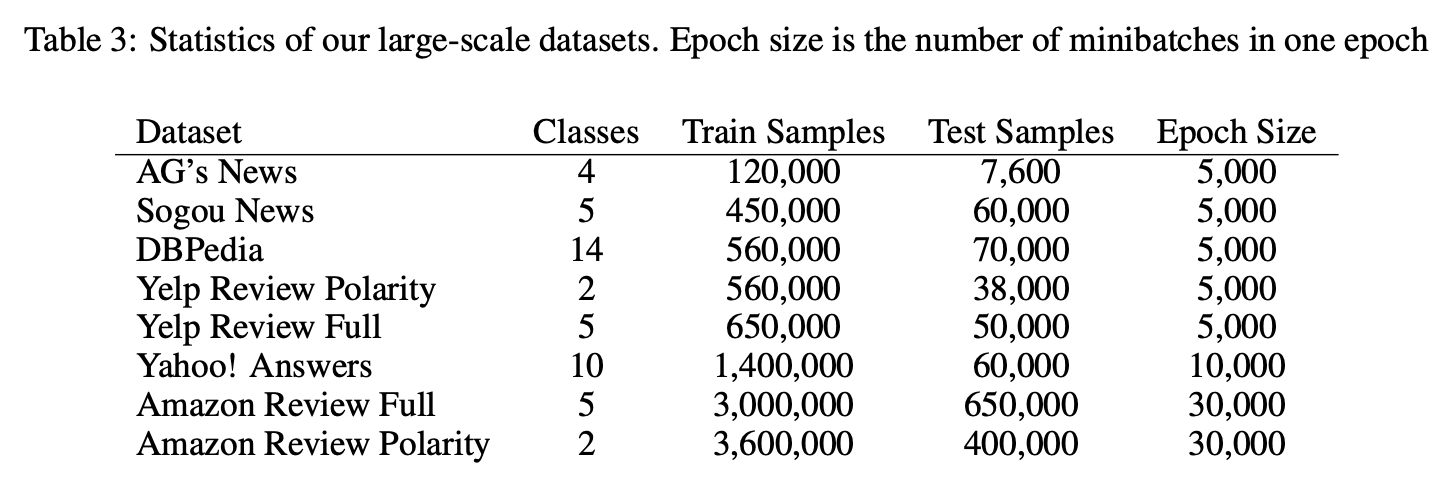
result 1.
모든 모델의 Training error를 비교한 결과입니다.
Lg,Sm은 제안하는 모델의 크기에 따른 분류이며, Full은 소문자 대문자를 구분하여 함께 사용한 모델을 의미합니다.

다음은 Character level ConvNet과 comparison model 사이의 error 차이를 comparison model 모델의 error로 나누어 시각화한 결과입니다.

위의 결과를 통해 다음의 사실들을 알 수 있습니다.
1) Character level ConvNet은 효과적인 방법임.
결과를 통해 Character level ConvNet의 성능이 뛰어남을 알 수 있었습니다.
이는 언어 또한 다른 종류의 신호(signal)과 전혀 다를 게 없다는 강한 증거라고 합니다.
아래는 첫번째 CNN layer의 가중치를 시각화 한 결과입니다.

2) 큰 데이터에서 더 좋은 성능을 보였음
이는 학습을 위해 많은 데이터를 필요로하는 CNN의 특성 때문입니다.
3) User가 만든 real world 데이터에 대해서 더 좋은 성능을 보임.
Character level ConvNet는 Amazon review 데이터셋과 같이 정교하게 작성되지 않은(less curated) 유저 데이터셋에서 더 좋은 성능을 보였습니다. 이는 모델이 실제 상황에서 더욱 뛰어난 성능을 보인다는 것을 알 수 있게 합니다.
4) 대문자를 추가하여 모델링하였을 때, 오히려 성능이 좋지 못했음.
저자들은 대, 소문자간의 의미차이가 실제로 존재하지 않기 때문에, 소문자만 사용했을때 regularization effect를 가져온다고 분석하였습니다.
5) 분류 작업에 따른 성능차이는 크지 않았음
6) Bag-of-means는 좋은 선택이 아니었음.
Word2Vec 기반의 k-means 클러스터링을 진행하여 임베딩하였을 때, 오히려 결과가 좋지 못했습니다.
distributed word representation을 단순하게 활용하여 역효과가 생겼다고 합니다.
마무리
Word-based CNN과 더불어 본 논문은 Text Classification을 위한 Character level의 CNN 모델을 제안하고 있습니다.
문자 기반의 CNN은 확실히 단어 기반의 방법과 비교하여 장, 단점이 존재합니다. 예를 들면, 단어 기반의 방법이 임베딩하지 못하는 단어를 문자 기반의 방법은 임베딩할 수 있습니다. FastText가 좋은 예시가 될 것 같습니다.
현재는 본 논문의 방법이 많이 사용되지는 않겠지만, 기존의 다양한 방법들을 잘 공부해 놓는게 중요하다고 생각합니다. 감사합니다.