1.Background
Sentence Summarization

Sentence Summarization은 Input Text의 핵심 의미를 포착하여 압축된 표현(Condensed representation = summary)을 생성하는 NLP Task로, 매우 중요한 동시에 어려운 과제 중 하나로 손꼽힙니다.
Sentence Summarization은 다음과 같은 수식으로 표현될 수 있습니다.
$$ \{\mathbf{x_1},...,\mathbf{x_M}\} \rightarrow \{\mathbf{y_1},...,\mathbf{y_N}\}$$
$$M>N$$
우선, 요약 될 문장은 \(M\)개의 단어 \(\mathbf{x_1},...,\mathbf{x_M}\)로 구성된 sequence입니다.
각각의 단어 \(\mathbf{x}_i\)는 \(|V|\) 크기의 Vocabulary \(\mathcal{V}\)로 부터 정의된 indicator vector로, \(\mathbf{x_i} \in \{0,1\}^V\,\,for\,\,i \in \{1,...,M\}\)를 만족합니다.
(One-hot encoding을 생각하시면 편하실 것 같습니다.)
결과적으로 Input sequence는 모델을 통해 \(N\)개의 단어로 구성된 output sequence \(\mathbf{y_1},...,\mathbf{y_N}\)로 요약됩니다.
보통의 경우 동일한 Vocabulary \(\mathcal{V}\) 에서 Output words가 선택되기 때문에, \(\mathbf{y_i}\)역시 \(y_i \in \{0,1\}^V\,\,for\,\,i \in \{1,...,N\}\)을 만족하는 indicator vector 형태입니다.
또한 요약을 진행하였기 때문에 Output sequence의 길이는 Input sequence의 길이보다 짧습니다. \((N<M)\)
Types of Summarization

Text Summarization는 모델을 거쳐 생성된 output(summary)의 형태에 따라 Abstractive summarization(생성 요약)과 Extractive summarization(추출 요약)으로 구분됩니다.
1)Abstractive summarization

Abstractive summarization(생성 요약)은 기존 Input text를 그대로 인용하지 않고, 기존의 내용을 새롭게 re-phrasing 하여 Summary를 생성하는 요약 모델입니다.
보통의 사람은 글을 요약할 때 paraphrasing, generalization, reordering과 같은 작업을 수행한다고 알려져 있습니다.
이처럼 우리의 요약 방법은 모든 문장을 그대로 인용하여 사용하지 않습니다. 따라서 우리가 보편적으로 문서를 요약하는 방법이 Abstractive summarization에 가깝다고 할 수 있습니다.
하지만 Abstractive suumarization은 내용을 처음부터 bottom-up 하는 과정으로 summary를 작성해야 합니다.
따라서 좋은 요약을 위해서는 representation, inference, generation과 같은 언어에 대한 고수준의 이해를 요구합니다.
이러한 이유로 Abstractive summarization은 Extractive summarization에 비해 상대적으로 우수한 성능을 보이기 어렵다고 할 수 있습니다.
$\DeclareMathOperator*{\argmax}{argmax}$
Abstractive summarization을 수식으로 나타내면 다음과 같습니다.
$$Abstractive:\,\argmax\limits_{\mathbf{y}\in \mathcal{Y}} s(\mathbf{x},\mathbf{y})$$
우선 \(\mathcal{Y}\)는 길이가 N인 모든 가능한 output summary의 집합입니다.
따라서 \(\mathcal{Y} \subset (\{0,1\}^V,...,\{0,1\}^V)\)를 만족합니다.
또한 가능한 모든 input sequence의 집합은 \(\mathcal{X}\)로 표현합니다.
\(s\)는 \(\mathbf{x}\), \(\mathbf{y}\) 쌍에 대한 평가를 내려주는 scoring function으로, \(s : \mathcal{X}\times \mathcal{Y} \rightarrow \mathbb{R}\)를 만족하는 함수가 될 것입니다.
따라서 본 수식은 input \(\mathbf{x}\)와 output \(\mathbf{y}\)를 고려하여 가장 높은 \(s(\mathbf{x},\mathbf{y})\)를 갖도록 하는 output sequence \(\mathbf{y}\)를 선택하는 과정을 의미한다고 할 수 있습니다. 여기에는 summary의 단어 선택에 대한 어떠한 제약이 존재하지 않습니다.
2)Extractive summarization

반면에 Extractive summarization(추출 요약)은 기존 Input text에 존재하는 중요한 단어를 그대로 사용하여 Summary를 생성하는 요약 모델입니다.
대부분의 요약모델이 Extractive 방법에 속하며, Summary를 생성하기 위해 텍스트의 일부를 그대로 인용하고 연결하는 추출(extractive) 방식을 사용합니다.
이전에 리뷰한 TextRank 알고리즘이 Extractive summarization의 좋은 예시가 될 것 같습니다.
Extractive summarization를 수식으로 나타낸다면 다음과 같습니다.
$$Extractive:\,\argmax\limits_{m\in \{1,...M\}^N}s(\mathbf{x},\mathbf{x_{[m_1,...,m_N]}})$$
길이 N의 \(\mathbf{y}\)를 summary로 생성하는 Abstractive summarization과 비교해 본다면,
Extractive summarization은 길이 N의 \(\mathbf{x_{[m_1,...,m_N]}}\)를 input \(\mathbf{x}\)로 부터 그대로 추출하여 scoring function을 계산함을 알 수 있습니다.
Input 문장에서 단어의 순서를 유지한 채로 불필요한 단어만을 삭제하는 deleting 방법을 사용한다면, 다음과 같이 \((m_{i-1}<m_i)\) 제약을 추가해주면 됩니다.
$$Extractive(deleting):\,\argmax\limits_{m\in \{1,...M\}^N,m_{i-1}<m_i}s(\mathbf{x},\mathbf{x_{[m_1,...,m_N]}})$$
Scoring function
scoring function \(s\)에 대하여 자세히 알아보도록 하겠습니다.
$$s(\mathbf{x},\mathbf{y}) \approx \sum_{i=0}^{N-1}g(\mathbf{y_{i+1},\mathbf{x},\mathbf{y_c}})$$
본 식은 \(s\)가 임의의 함수 \(g\)를 통해 i번째 시점에서의 \(\mathbf{y_{i+1}}\),\(\mathbf{x}\), \(\mathbf{y_c}\)를 함께 고려하여 계산되야 함을 의미하고 있습니다.
\(g\)는 어떤 함수이며 변수들을 어떻게 고려해야 할까요?
설명에 앞서 각각의 notation에 대해 말씀드리도록 하겠습니다.
\(\mathbf{x}\)는 전체 input sequence를,
\(\mathbf{y_{i+1}}\)는 i번째 시점에서 \(i+1\)번째 output 단어를 의미합니다.
\(\mathbf{y_c}\)는 조금 생소해 보일 수 있으나, i번째 시점 이전에 출력된 window size C 내의 단어 집합입니다.
즉 [i-C+1, ..., i-1, i] 시점의 출력 단어를 의미합니다.
간단히 표현하면 \(\mathbf{y_c} \triangleq \mathbf{y_{[i-C+1,...,i]}}\)가 될 것입니다.
Notation을 고려해 보신다면, 어떠한 형태의 \(g(\mathbf{y_{i+1},\mathbf{x},\mathbf{y_c}})\)가 떠오르시나요?
$$\prod_{i=1}^{N}P(w_{i}| w_{1}, w_{2}, ... , w_{i-1})$$
맞습니다. 순차적으로 i번째 요소들을 고려하여 i+1 번째 output을 생성한다는 관점에서 이는 언어모델(language model)과 유사합니다.
따라서 쉽게 \(s(\mathbf{x},\mathbf{y}) = p(\mathbf{y}|\mathbf{x},\mathbf{y_c};\theta)\)를 고려해 볼 수 있습니다.
그렇다면, 이제 scoring function은 다음과 같은 conditional log-probability로 다시 쓰일 수 있습니다.
$$s(\mathbf{x},\mathbf{y}) =logp(\mathbf{y}|\mathbf{x};\theta) \approx \sum_{i=0}^{N-1}logp(\mathbf{y+1}|\mathbf{x},\mathbf{y_c};\theta)$$
2. Neural Abstractive Summarization Model
Abstractive summarization은 더 어려운 생성 문제를 해결해야 하지만, extraction에 비해 상대적으로 강한 제약을 두고 있지 않습니다. 따라서 Abstractive summarization 모델은 생성과정에 있어 더 자유로울 수 있으며, 보다 넓은 범위의 훈련 데이터에 적합시킬 수 있습니다.
2015년에 발표된 본 눈문은 이러한 Abstractive summarization을 위한 scoring function \(\mathbf{s}\)의 모델링에 대해 다루고 있습니다.
scoring function에 conditional log-probability의 개념을 대입한다면,
이제 본 논문의 구체적인 목적은 local conditional distribution \(p(\mathbf{y_{i+1}}|\mathbf{x},\mathbf{y_c};\theta )\)의 모델링이라고 할 수 있을 것 입니다
Model architecture
우리가 찾으려는 \(p(\mathbf{y_{i+1}}|\mathbf{x},\mathbf{y_c};\theta )\)는 input sentence \(\mathbf{x}\)에 대한 조건부 확률 형태의 언어모델입니다.
논문이 발표될 당시 기존의 summarization 모델들은 다음과 같이 언어모델과 조건부 확률을 독립적인 모델로 나누어 계산하였습니다.
$$\argmax\limits_y logp(\mathbf{y}|\mathbf{x}) = \argmax\limits_y logp(\mathbf{y})p(\mathbf{x}|\mathbf{y})$$
하지만 본 논문에서는 Neural machine translation의 방법을 차용하여, 구하려는 분포인 \(p(\mathbf{y_{i+1}}|\mathbf{x},\mathbf{y_c};\theta )\)를 하나의 신경망에 directly parameterizing 합니다.
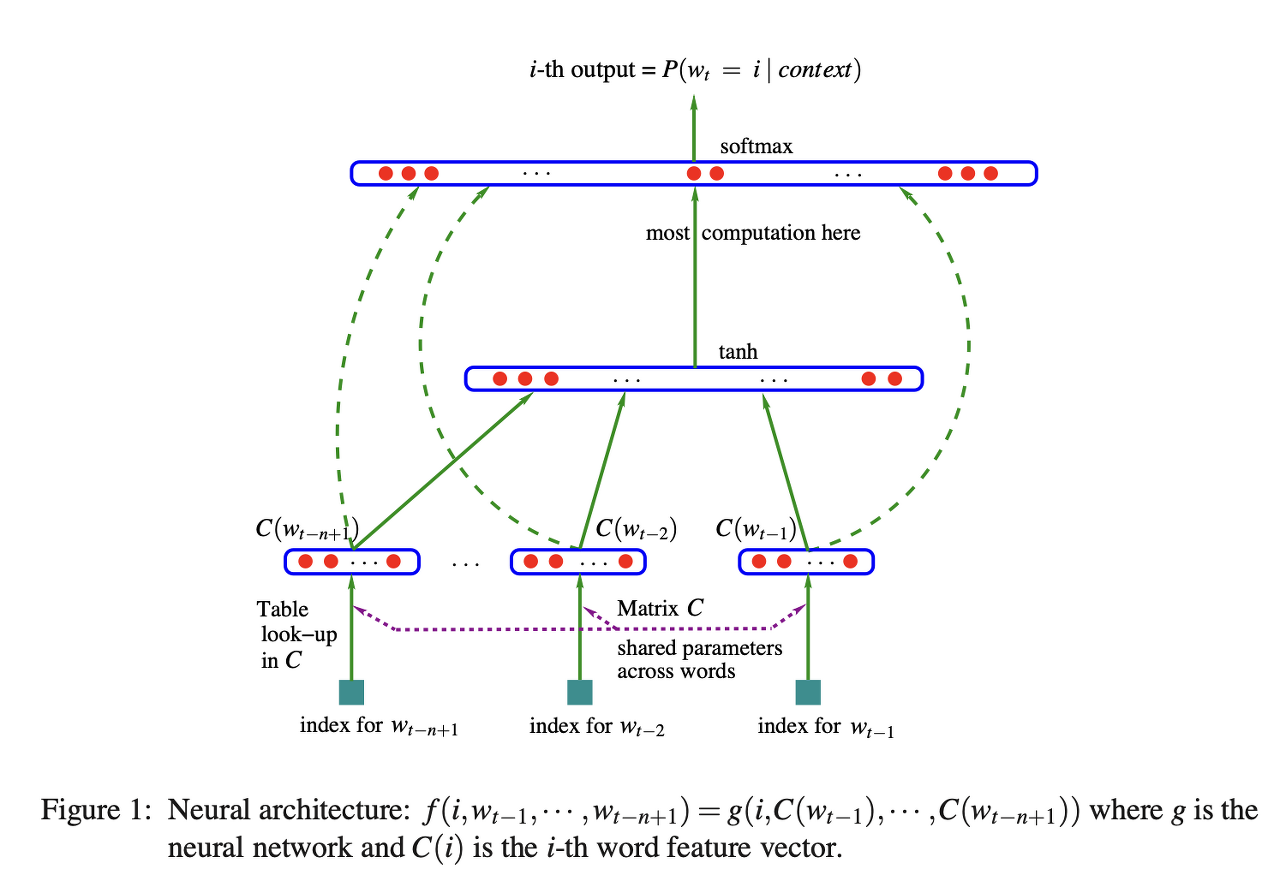
directly parameterizing의 핵심은 다음 단어의 context probability를 추정하기 위한 언어 모델에 있습니다.
NNLM은 언어 모델을 directly parameterizing 할 수 있는 가장 기본적인 형태의 신경망 모델로, 본 논문에서 probabilistic language model을 모델링하기 위한 base model로 사용됩니다.
NNLM에 대한 자세한 설명이 필요하신 분 께서는 먼저 아래의 리뷰를 참고 부탁드립니다.
[자연어처리][paper review] NNLM : A Neural Probabilistic Language Model
본 논문을 통해 처음 소개된 NNLM(Neural Network Language Model)은 word2vec의 기초가 되는 논문으로 2003년 발표되었습니다. count based word representation이 많이 사용되면 당시, language modeling을 어렵..
supkoon.tistory.com
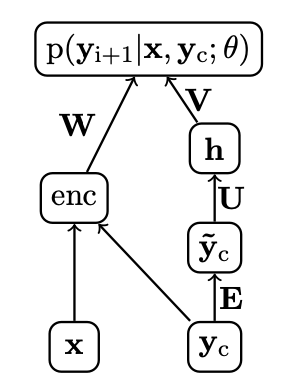
따라서 제안하는 모델은 "Neural" Abstractive Summarization Model이라고 할 수 있습니다.
이제 모델에 대해 자세히 들여다 보도록 하겠습니다.
제안하는 모델은 그림과 같이 NNLM에 encoder가 더해진 구조입니다. encoder를 제외한다면 NNLM과 사실상 동일합니다.
수식으로 나타낸다면, 다음과 같이 인코더와 비선형 활성화 함수를 포함하는 Neural Language Model이 될 것입니다.
$$p(\mathbf{y_{i+1}}|\mathbf{y_c},\mathbf{x};\theta) \propto exp(\mathbf{V}\mathbf{h} + \mathbf{W}enc(\mathbf{x},\mathbf{y_c})),$$
$$\tilde{\mathbf{y_c}} = [\mathbf{E}\mathbf{y_{i-C+1}},...,\mathbf{E}\mathbf{y_i}],$$
$$\mathbf{h} = tanh(\mathbf{U}\tilde{\mathbf{y}}_c)$$
encoder의 output \(enc(\mathbf{x},\mathbf{y_c})\)과 hidden layer output \(\mathbf{h}\)를 함께 고려하여 출력 \(p(\mathbf{y_{i+1}}|\mathbf{y_c},\mathbf{x};\theta)\)를 내놓음을 알 수 있습니다.
Notation과 함께 간략한 설명을 드리도록 하겠습니다.
\(C\)는 앞서 설명드린 대로 window size를,
\(D\)는 word embedding size를,
\(H\)는 hidden layer \(\mathbf{h}\)의 크기(유닛 수)를 의미합니다.
그리고 \(\theta\)는 모델 parameter들의 집합으로 \(\theta = (\mathbf{E},\mathbf{U},\mathbf{V},\mathbf{W})\) 입니다.
\(\mathbf{E}\)는 window size C 이내의 출력단어들인 \(\mathbf{y_c}\)를 \(\tilde{\mathbf{y}}_c\)로 임베딩 하기위해 사용됩니다.
따라서 \(\mathbf{E}\)는 \(\mathbf{E} \in \mathbb{R}^{D\times V}\)인 word embedding matrix입니다.
두번째로 \(\mathbf{U}\)는 임베딩된 \(\tilde{\mathbf{y}}_c\)를 hidden layer \(\mathbf{h}\)로 입력시켜주는 역할을 합니다.
따라서 \(\mathbf{U}\)는 \(\mathbf{U} \in \mathbb{R}^{(CD)\times H}\)인 weight matrix 입니다.
\(\mathbf{V}\)는 hidden layer \(\mathbf{h}\)의 output을 output layer로 입력시켜주는 역할을 합니다.
따라서 \(\mathbf{V}\)는 \(\mathbf{V} \in \mathbb{R}^{V\times H}\)인 weight matrix 입니다.
마지막으로 \(\mathbf{W}\)는 encoder의 output을 output layer로 입력시켜주는 역할을 합니다.
따라서 \(\mathbf{W}\)는 \(\mathbf{W} \in \mathbb{R}^{V\times H}\)인 weight matrix 입니다.
종합하여 보면, 제안하는 모델은 입, 출력을 동시에 고려하는 인코더를 사용하여 Context를 반영한 출력(요약)을 생성한다고 할 수 있습니다.
Encoder
encoder는 \(\mathbf{x}\), \(\mathbf{y_c}\)를 input으로 받아 함께 학습하면서 Context를 생성과정에 포함시킬 수 있도록 하는 역할을 합니다.

저자들은 그림에서 black box로 표현된 Encoder(enc)를 위해 사용할 수 있는 세가지 구조를 제안하고 있습니다.
1) Bag-of-Words Encdoer

Bag-of-Words Encdoer(\(enc_1\))는 input sentence의 각 단어를 \(H\)차원으로 임베딩하여 동일한 가중치\(1\over M\)로 반영하는 방법입니다.
$$\tilde{\mathbf{x}} = [\mathbf{F}\mathbf{x_1},...,\mathbf{F}\mathbf{x_M}]$$
\(\mathbf{F}\)는 \(V\)차원의 각 단어를 \(H\)차원으로 매핑해주는 embedding matrix로 \(\mathbf{F}\in \mathbb{R}^{H\times V}\)입니다.
$$\mathbf{p} = [1/M,...,1/M]$$
$$enc_1(\mathbf{x},\mathbf{y_c}) = \mathbf{p}^T\tilde{\mathbf{x}},$$
Uniform distribution을 적용하여 동일한 가중치를 부여합니다. Bag-of-Words Encdoer는 \(\mathbf{y_c}\)를 사용하지 않습니다.
2) Convolution Encoder
Convolution Encoder는 local Interaction을 학습할 수 있도록 input sentence에 temporal convolution을 적용하는 방법입니다.
temporal convolution은 시퀀스를 다룰 때 많이 사용하는 CNN의 일종입니다.
일반적으로 이미지 처리를 위해 수행되는 convolution 계산이 2개의 축을 따라 움직이는 것과는 다르게, 시퀀스를 다루기 위한 convolution은 시퀀스의 흐름에 따른 축으로만 이동하며 1-D convolution 계산을 수행합니다.
$$\tilde{\mathbf{x}}^0 = [\mathbf{F} \mathbf{x_1},...,\mathbf{F} \mathbf{x_M}]$$
우선 각각 단어를 \(H\)차원의 임베딩 합니다.
$$\forall i,l \in \{1,...,L\},\,\,\bar{\mathbf{x}}_{i}^l = \mathbf{Q}^l\tilde{\mathbf{x}}^{l-1}_{[i-Q,...,i+Q]}],$$
$$\forall i,l \in \{1,...,L\},\,\,\tilde{\mathbf{x}}_{j}^l = tanh(\max\{\bar{\mathbf{x}}_{2i-1}^l,\bar{\mathbf{x}}_{2i}^l\}),$$
convoltion, max-pooling, activation function \(tanh\)를 포함하는 \(L\)개의 deep convolution layer를 거칩니다. \(\mathbf{Q}^{L\times H\times 2Q+1}\)는 각 layer의 필터 집합을 의미합니다.
$$\forall j, enc_2(\mathbf{x},\mathbf{y_c})_j = \max\limits_i \tilde{\mathbf{x}}_{i,j}^L,$$
L번째 convolution layer의 output을 종합하여 가장 큰 하나의 output만을 내놓습니다.(max over time)
역시 \(\mathbf{y_c}\)를 사용하지 않습니다.
3) Attention-Based Encoder
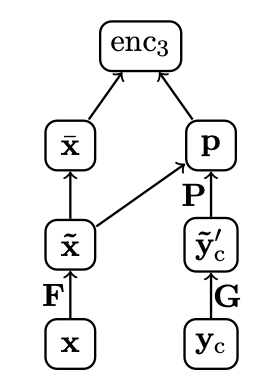
마지막으로 Attention-Based Encoder(\(enc_3\))은 Bahadanau Attention을 사용하여 Input과 Output을 모두 고려할 수 있는 attention based contextual encoder 입니다.
앞선 방법들에 비해 전체 input sentence에 대한 single representation을 계산할 수 있다는 장점 또한 존재합니다.
$$\tilde{\mathbf{x}} = [\mathbf{F} \mathbf{x_1},...,\mathbf{F} \mathbf{x_M}],$$
역시 각각 단어를 \(H\)차원의 임베딩 합니다.
$$\tilde{\mathbf{y}}_c^{'} = [\mathbf{G} \mathbf{y}_{i-C+1},...,\mathbf{G} \mathbf{y_i} ]$$
Context \(\mathbf{y_c}\)또한 \(D\)차원으로 임베딩합니다.
$$\tilde{\mathbf{x}} \propto exp(\tilde{\mathbf{x}} \mathbf{P} \tilde{\mathbf{y}}_c^{'}),$$
학습 가능한 Attention matrix \(\mathbf{P \in \mathbb{R}^{H\times (CD)}}\)를 도입하여 임베딩된 \(\tilde{\mathbf{x}}\) \(\tilde{\mathbf{y}}_c^{'}\) 사이의 Attention alignment을 계산합니다.
$$\forall i\,\,\bar{\mathbf{x}_i} = \sum_{q=i-Q}^{i+Q}\tilde{\mathbf{x}}_i/\mathbf{Q}$$
i번째 위치의 \(\tilde{\mathbf{x_i}}\)에서 attention alignment가 강하게 일어났을 때, 주변 단어들에게도 영향을 나누어 주도록 smoothing window \(\mathbf{Q}\)를 적용합니다.
$$enc_3(\mathbf{x},\mathbf{y_c}) = \mathbf{p}^T\bar{\mathbf{x}},$$
\(\bar{\mathbf{x}}\)에 attention alignment \(p\)를 적용하여 인코딩 결과를 얻습니다.
본 논문에서는 최종적으로 Attention based encoder 구조를 선택하였습니다.
아래의 그림은 학습된 attention alignment의 distribution을 시각화 한 예시입니다.

Training
추출방식에 비해 생성 요약은 생성 과정에서의 단어 선택에 대한 제약이 완화되어 있습니다.
따라서 생성 요약은 임의의 input, output pair \((\mathbf{x}^{(1)},\mathbf{y}^{(1)}),...,(\mathbf{x}^{(J)},\mathbf{y}^{(J)})\)에 대하여 폭넓게 학습이 가능합니다.
손실함수로는 NLL이 사용됩니다.
$$NLL(\theta) = -\sum_{j=1}^J logp(\mathbf{y}^{(j)}|\mathbf{x}^{(j)};\theta),$$
$$=-\sum_{j=1}^J\sum_{i=1}^{N-1}logp(\mathbf{y_{i+1}}^{(j)}|\mathbf{x}^{(j)},\mathbf{y_c};\theta)$$
Generating
학습된 모델을 사용한 Generation은 다음과 같이 scoring function을 최대로 하는 output \(mathbf{y}\)를 찾는 과정으로 진행됩니다.
$$\mathbf{y}^* = \argmax\limits_{\mathbf{y}\in\mathcal{Y}} \sum_{i=0}^{N-1} g(\mathbf{y}_{i+1},\mathbf{x},\mathbf{y}_c)$$
또한 생성 과정에서 beam-search가 사용되었습니다.

Extractive Tuning
Attention 기반의 생성 요약 모델은 효과적인 성능을 보여줍니다.
하지만 생성모델은 고유명사와 같이 중요한 단어를 제외할 가능성이 존재합니다.
Extractive Tuning은 모델이 extractive/abstractive 사이의 trade-off를 고려할 수 있도록 몇가지의 특성집합을 추가하여 Tuning을 진행하는 과정을 의미합니다.
기존에 scoring function은 다음과 같이 정의되었습니다.
$$s(\mathbf{x},\mathbf{y}) \approx \sum_{i=0}^{N-1}g(\mathbf{y_{i+1},\mathbf{x},\mathbf{y_c}})$$
Tuning은 scoring function의 \(g\)를 \(g(\mathbf{y}_{i+1},\mathbf{x},\mathbf{y}_c) \triangleq \alpha^T f(\mathbf{y}_{i+1} ,\mathbf{x}, \mathbf{y}_c)\)로 설정하여 계산합니다.
\(f\)는 여러개의 특성을 생성해주는 특성 함수를, \(\alpha\)는 생성된 각 특성에 대한 가중치를 의미합니다.
$$s(\mathbf{x},\mathbf{y}) = \sum_{i=0}^{N-1} \alpha^T f(\mathbf{y}_{i+1} ,\mathbf{x}, \mathbf{y}_c)$$
특성 함수\(f\)는 아래와 같은 특성 집합을 사용하여 기존의 scoring function이 다양한 extractive feature를 학습할 수 있도록 합니다.
$f(\mathbf{y}_{i+1},\mathbf{x},\mathbf{y}_c) = [\,\,\log p(\mathbf{y}_{i+1}|\mathbf{x},\mathbf{y}_c;\theta),$(base)
$\mathbb{1}\{\exists j. \mathbf{y}_{i+1} = \mathbf{x}_j\},$ (1-gram)
$\mathbb{1}\{\exists j. \mathbf{y}_{i+1-k} =\mathbf{x}_{j-k}\forall k \in \{0,1 \}\},$ (2-gram)
$\mathbb{1}\{\exists j. \mathbf{y}_{i+1-k} =\mathbf{x}_{j-k}\forall k \in \{0,1,2 \}\},$ (3-gram)
$\mathbb{1}\{\exists k<j. \mathbf{y}_{i} = \mathbf{x}_k,\mathbf{y}_{i+1} = \mathbf{x}_j \}\,\,]$ (re-ordering)
따라서 5개 특성의 가중치를 반영해주는 파라미터 \(\alpha\)는 \(\alpha \in \mathbb{R}^5\)가 됩니다.
Extractive Tuning은 기존 모델의 학습을 마친 후에, 모델 파라미터 \(\theta\)를 고정하고 \(\alpha\)를 Tuning하는 방법으로 진행됩니다.
3.Results
실험은 뉴스 기사 데이터셋인 DUC-2004 데이터셋과 Gigaword 데이터셋이 사용되었습니다.
DUC-2004 데이터셋은 사람이 직접 작성한 reference summary를 포함하고 있으며,
Gigaword 데이터셋은 각 기사의 헤드라인을 summary로 정의하고 첫 번째 문장과 연결시켜 input-summary pair를 생성하였습니다.
성능 비교를 위한 Metric으로는 Rouge score와 Perplexity가 사용되었습니다. Rouge score는 machine translation과 같은 언어모델의 generation 성능을 평가하기 위해 사용되는 대표적인 Metric입니다. $$ROUGE-N = {{\sum_{S\in \{Reference\,Summaries\}} \sum_{gram_n \in S}Count_{match}(gram_n)} \over {\sum_{S\in \{Reference\,Summaries\}} \sum_{gram_n \in S}Count(gram_n)}}$$ Rouge에 대한 자세한 사항은 아래의 리뷰를 참고 부탁드립니다.
[자연어처리][Metric] ROUGE score : Recall-Oriented Understudy for Gisting Evaluation
ROUGE ROUGE(Recall-Oriented Understudy for Gisting Evaluation)는 text summarization, machine translation과 같은 generation task를 평가하기 위해 사용되는 대표적인 Metric입니다. 본 글의 내용은 ROUGE s..
supkoon.tistory.com
Perplexity 역시 언어모델의 성능을 평가하는 대표적인 metric 입니다.
$$Perplexity=\sqrt[N]{\frac{1}{P(w_{1}, w_{2}, w_{3}, ... , w_{N})}}=\sqrt[N]{\frac{1}{\prod_{i=1}^{N}P(w_{i}| w_{1}, w_{2}, ... , w_{i-1})}}$$
perplexity에 대한 자세한 설명 또한 아래의 리뷰를 참고 부탁드립니다.
[자연어처리][Metric] Perplexity
Perplexity Perplexity는 BLEU, ROUGE와 더불어 언어모델의 Generation 성능을 판단할 수 있는 지표입니다. Machine translation, text summarization과 같은 Generation task의 성능 비교를 위해 주로 사용됩니..
supkoon.tistory.com
result 1.
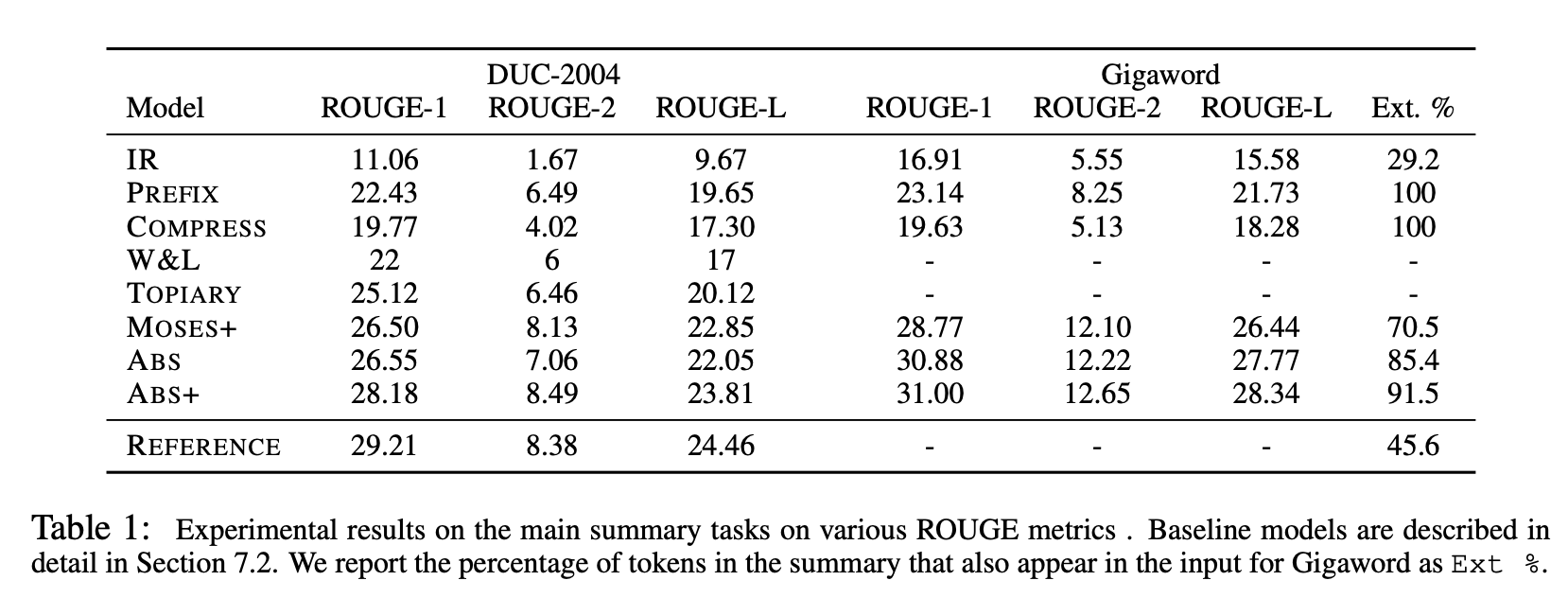
Rouge score를 사용하여 Summarization 성능을 비교한 결과입니다.
Ext. %는 Extract %를 의미하며, 따라서 input과 output의 토큰이 겹칠 확률입니다. extractive 모델에 대해서는 100%가 나오게 됩니다.
제안하는 모델인 ABS가 baseline 모델과 비교할 때 가장 우수한 요약 성능을 보였음을 알 수 있습니다.
result 2.
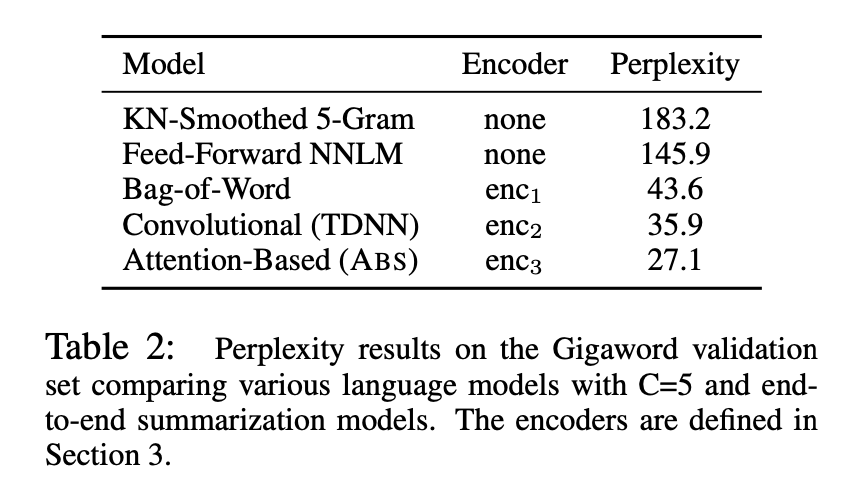
인코더의 종류에 따른 Perplexity 성능의 비교입니다.
Perplexity가 가장 낮은 Attention based encoder(\(enc_3\))가 가장 우수한 성능을 보였음을 알 수 있습니다.
result 3.

생성과정에 있어서 Greedy method와 beam search method 간의 Rouge score 비교입니다.
제안하는 모델인 ABS+에 Beam search를 적용하였을 때 생성과정에서 가장 좋은 성능을 보여주었음을 알 수 있습니다.
result 4.

실제로 Gigaword 데이터셋에서 생성요약을 진행한 결과 샘플입니다.
예시 7과 같이 실패한 경우도 존재하지만, 예시 4에서는 생성요약모델이 New zealand를 nz로 re-wording 하였음을 확인할 수 있습니다.
마무리
본 논문은 contextual encoder를 사용하는 Neural Abstractive Summarization 모델을 제안하고 있습니다.
기존의 Abstractive summarization 방법과는 다르게, 제안하는 모델은 언어모델에 기반하여 scoring function을 신경망에 directly parameterizing 하였습니다.
또한 contextual encoder로 사용가능한 세가지 구조 BoW, CNN, Attention를 소개하였는데, Attention based encoder가 가장 좋은 성능을 보였습니다.
수식과 내용이 많은 논문인지라 시간이 많이 소요되었지만, 배울게 많았던 논문인 것 같습니다. 감사합니다.