CNN
CNN은 컴퓨터 비전 분야를 위해 개발되었으며, 대중적으로 사용되고 있는 가장 보편화된 이미지 처리 알고리즘입니다.
CNN은 가중치를 갖는 필터를 사용하기 때문에 개별 픽셀에 대한 가중치를 고려하지 않아도 됩니다.
따라서 CNN을 사용하는 모델은 파라미터를 효율적으로 사용하여 매우 큰 차원의 이미지를 처리할 수 있습니다.


CNN in NLP
CNN은 자연어 처리를 위해서도 효과적으로 사용되고 있습니다.
실제로 전통적인 일부 자연어처리 Task의 경우, CNN이 훌륭한 성능을 보인 사례들이 존재합니다.
Sentence(Text,Document) Classifiction은 자연어처리의 가장 주된 Task 중 하나입니다.
2014년 발표된 본 논문은 CNN을 사용한 Sentence Classification 모델을 제안하고 있습니다.
우선 본 논문은 CNN과 Word2Vec 등의 언어모델에 대한 기본적인 이해를 필요로 합니다.
아래의 리뷰들 외에도 기존에 다양한 언어모델에 대한 리뷰를 진행하였습니다. 자세한 설명이 필요하신 분께서는 기존의 리뷰들을 참고 부탁드립니다.
[자연어처리][paper review] Word2Vec: Efficient Estimation of Word Representations in Vector Space
기존의 count based word representaion 방법들은 간단하지만, 단어 간의 유사도를 판단할 수 없습니다. 예를 들면, 삼겹살 [0,0,0,0,0,1] , 목살 [0,0,0,1,0,0] , 연필 [0,1,0,0,0,0] 세 개의 임베딩 된 단어가..
supkoon.tistory.com
[자연어처리] [paper review] Word2vec: Distributed Representations of Words and Phrases and their Compositionality
본 논문은 이전에 리뷰한 Word2vec의 후속 논문으로 같은해에 발표되었습니다. 따라서 전체적인 개념보다는 이전 논문에서 발표한 Skip-gram 방법론의 representation quality와 computation efficiency 개선을 목
supkoon.tistory.com
1. CNN for Sentence Classification
Input representation
모델을 위한 입력구조에 대해 먼저 설명드리도록 하겠습니다.
문장의 i번째 단어는 k차원의 임베딩으로 표현되어 아래와 같이 표기합니다.
\(\mathbf{x}_i \in \mathbb{R}^k\)
따라서 길이가 n인 문장은 아래와 같이 표현할 수 있습니다.
\begin{align} \mathbf{x}_{1:n} = \mathbf{x}_{1} \oplus \mathbf{x}_{2} \oplus \ldots \oplus \mathbf{x}_{n} \end{align}
\(\oplus\)는 단순한 concatenate를 표현하는 연산자 입니다.
일반화 한다면 i번째부터 j개 단어의 concatenation은 \(\mathbf{x}_{i:i+j}\)가 될 것입니다.
\begin{align} \mathbf{x}_{i:i+j} = \mathbf{x}_{i} \oplus \mathbf{x}_{i+1} \oplus \ldots \oplus \mathbf{x}_{i+j} \end{align}
Model architecture
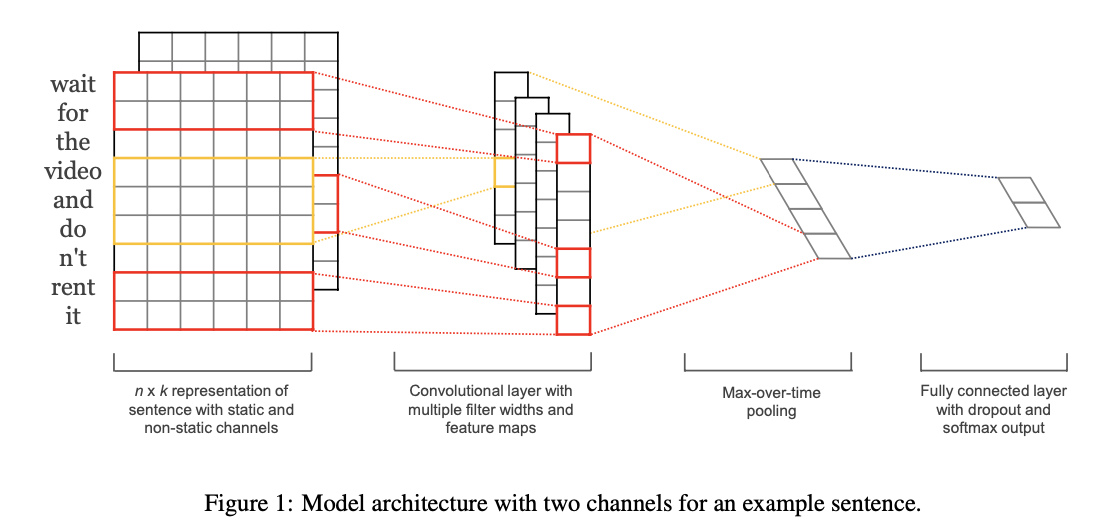
각각 k차원으로 임베딩된 h개 단어들에 적용되는 CNN \(filter\)는 \(\mathbf{w} \in \mathbb{R}^{hk}\)를 포함하고 있습니다.
일반적인 convolution 연산을 사용하여 일반화 한다면,
하나의 윈도우에 해당하는 \(\mathbf{x}_{i:i+h-1}\)로 부터 특성 \(c_i\)는 다음의 연산을 통해 생성될 것입니다.
\begin{align} c_i = f(\mathbf{w} \cdot \mathbf{x}_{i:i+h-1} + b) \end{align}
\(b \in \mathbb{R}\)는 bias를, \(f\)는 비 선형 활성화 함수를 의미합니다.

이 하나의 필터 \(\mathbf{w} \in \mathbb{R}^{hk}\)는 문장의 가능한 모든 window인 \(\{\mathbf{x}_{1:h}, \mathbf{x}_{2:h+1}, \ldots, \mathbf{x}_{n-h+1:n}\}\)에 각각 적용되어
아래의 feature map \(\mathbf{c} \in \mathbb{R}^{n-h+1}\)을 생성하게 됩니다.
$$\mathbf{c} = [c_{1}, c_{2}, \ldots , c_{n-h+1}]$$
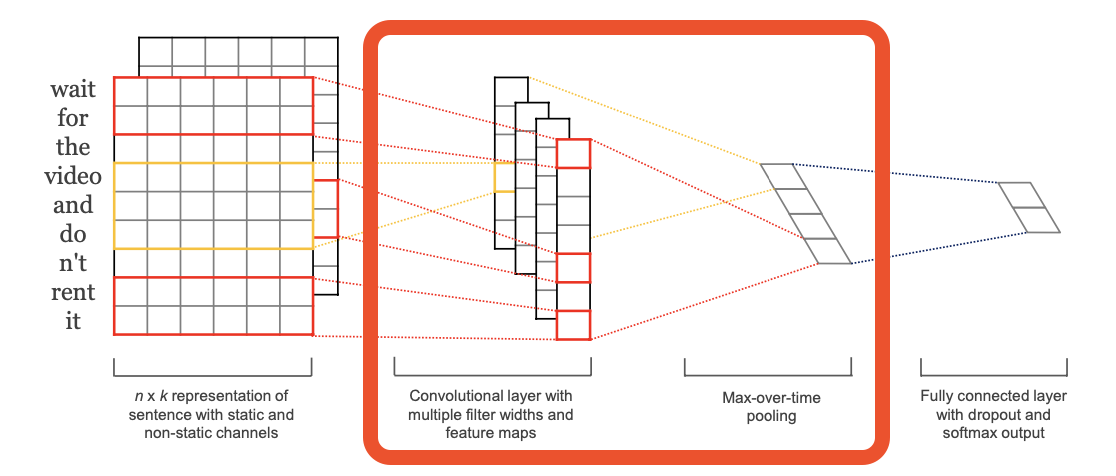
feature map \(\mathbf{c}\)는 이후에 max pooling을 거치게 됩니다.
$$\hat{c} = max\{\mathbf{c}\}$$
이는 하나의 feature map에 해당하는 하나의 특성이 추출됨을 의미합니다.(one feature from one filter)
저자들은 가장 중요한 하나의 특성만을 추출하기 위함이라고 얘기하고 있습니다.
또한 pooling은 다양한 길이의 문장을 다룰 수 있다는 장점이 있습니다.
제안하는 모델은 여러개의 필터를 사용하여 이러한 과정을 수행합니다.
각각의 필터는 하나의 특징을 추출 할 수 있을것이며, 결과적으로 모델은 여러개의 매우 중요한 특성을 추출해 낼 수 있을 것입니다.
본 모델은 다양한 variation이 존재할 수 있습니다.
Window size를 다르게 하는 필터들을 사용한다면, 보다 다양한 특성 추출을 기대해 볼 수 있을 것 입니다.
저자들은 task-specific하게 fine-tuning이 가능한 필터와 학습이 진행되지 않는 static 필터를 함께 사용하는 방법 또한 제시하고 있습니다.

여러개의 필터들로 부터 얻은 feature들은 fully-connected layer의 입력으로 사용됩니다.
그리고 최종적으로 모델은 softmax output layer를 통해 Positive / Negative를 Classification하게 됩니다.
Regularization
Dropout과 L2 regularization를 사용하는 것이 추가적인 정규화 방법이 될 수 있습니다.
fully-connected layer와 output layer 사이에 dropdout을 사용한다면 아래의 연산을 수행하게 됩니다.
$$y = \mathbf{w}\cdot (\mathbf{z} \circ \mathbf{r}) + b$$
\(r\)는 베르누이 분포로 부터 샘플링된 마스킹 벡터 (\(r \in \mathbb{R}^m\))로 element-wise 연산 \(\circ\)을 통해 모델에 적용됩니다.
2.Results

저자들은 7개의 데이터셋을 활용하여 검증과정을 진행하였습니다.
각각 데이터셋에 대한 정보는 다음과 같습니다.
\(c\) : 클래스 수
\(l\) : 평균 문장 길이
\(N)\ : 데이터셋 크기
\(|V|\) : Vocabulary 크기
\(|V_{pre}|\) : 사전학습을 위해 사용된 단어의 수
\(Test\) : 테스트셋의 크기 입니다. CV는 10-fold 교차검증을 의미합니다.
result 1.

검증 과정에서는 4개의 variant model들이 사용되었습니다.
CNN-rand : baseline 모델로, 모든 파라미터가 랜덤초기화되어 학습되는 모델입니다.
CNN-static : pretrained Word2Vec를 사용하여 임베딩을 업데이트하지 않고, 다른 모델 파라미터만을 업데이트 하는 모델입니다.
CNN-non-static : CNN-static과 같은 방법이지만, 임베딩 또한 포함하여 업데이트를 진행합니다.
CNN-multichannel : 업데이트 가능한 non-static 필터와 업데이트 불가능한 static 필터를 동시에 사용하는 모델입니다.
우선 CNN-rand는 좋은 성능을 보이지 못했습니다.
하지만 CNN-static 모델의 성능을 통해, Pre-trained 임베딩을 사용한다면 매우 뛰어난 결과를 보인다는 사실을 알 수 있었습니다.
또한 대부분의 Task에서 CNN-static모델에 비해 CNN-non-static의 성능이 좋았다는 점에서 Fine-tuning이 성능개선에 도움을 준다는 사실을 알 수 있었습니다.
다음은 Static 모델과 Non-static 모델의 실제 결과를 비교한 Table 입니다.

첫번째 행의 bad vs good vs terrible의 예시를 통해 fine-tuning을 진행한 쪽이 더 의미적으로 맞는 표현을 학습하였다는 것을 직관적으로 알 수 있습니다.
마지막으로 CNN-multichannel은 overfitting을 방지해줄 것이라는 기대하에 제안된 모델이었습니다. 하지만 Dropout과 같은 기존의 정규화 방법들이 잘 작동하여 추가적인 성능개선을 얻을 수는 없었습니다.
마무리
본 논문은 CNN을 활용한 Sentence Classification 모델을 제안하고 있습니다.
논문이 매우 잘 읽힐정도로 어렵지 않으며, 다양한 모델비교를 진행하였다는 점이 눈이 띄었던 것 같습니다.
고정관념에 갇혀있지 않고, 모델의 장점을 고려하여 적용하였다는 점 또한 좋았던 것 같습니다.
CNN은 파라미터 수를 줄여 빠른 추론,학습이 가능하다고 생각하는데, 한편으로는 이 부분에 대한 검증 또한 있었으면 좋았을 것 같다는 생각이 들었습니다. 감사합니다.