FastText는 2017년 Facebook AI research 팀에서 발표한 논문으로,
제목 그대로 subword information을 사용하여 word representation의 품질을 enriching 하는 방법을 제시합니다.
word2vec를 시작으로 unlabeled corpora를 사용하여 학습한 Continuous word representation은 많은 NLP task에 유용하게 사용되고 있습니다. 이러한 모델들은 하나의 단어에 distinct한 vector를 할당합니다.
이러한 embedding 방법은 단어를 형성하는 morphology(형태소)를 고려하지 않기 때문에 매우 큰 vocabulary 혹은 매우 rare한 단어를 위한 좋은 방법이 아닐 수 도 있습니다.
특히 터키어, 핀란드어, 한국어와 같이 단어의 morphology가 풍부한 언어를 학습하는 경우가 그러한 예시가 될 것입니다.
따라서 저자들은 word2vec의 skip-gram 모델을 기반으로 다양한 크기의 n-gram을 활용하여 morphology를 반영할 수 있는 개선된 word representation 방법론을 제안 합니다.
1.general skip-gram
FastText는 skip-gram을 base로 한 모델이기 때문에 비교를 위하여 간단하게 skip-gram model에 대하여 설명드리도록 하겠습니다.
skip-gram은 사이즈 \(W\)의 vocabulary에서 각 단어 \(w \in \{1,...,W\}\) 의 vector representation을 만들어주는 방법 중 하나입니다.

general한 skip-gram은 위의 그림과 같이 각각의 input words \(w\)에 대하여 window 안의 context words를 예측하는 방법으로 학습이 진행됩니다. 따라서 objective function는 아래와 같이 context words의 softmax probability를 maximize하게 됩니다.

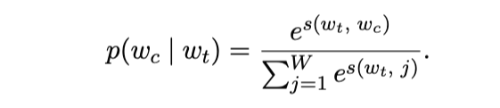
하지만 이러한 방법은 각각의 \(w_c\)하나를 예측하기 위해 모든 단어를 고려해야하는 계산 효율 관점에서의 단점이 존재합니다.
따라서 대중적으로 함께 사용되는 방법이 바로 "negative sampling" 입니다.
negative sampling은 context words를 제외한 window 밖의 words를 sampling하여
Context words를 예측하는 multi label classification이 아닌,
context words 인지, 아닌지를 예측하는 binary classification 문제로 objective function을 치환합니다.
이 과정에서 skip-gram은 output layer의 계산효율성을 얻을 수 있습니다.
따라서 negative sampling에 의해 개선된 skip-gram의 objective function은 다음과 같습니다.
positive sample에 해당하여 합이 최대화 되는 log likelihood와는 다르게,
negative sample에 해당하는 log likelihood는 -1이 곱해져 합이 최소화됨을 확인할 수 있습니다.

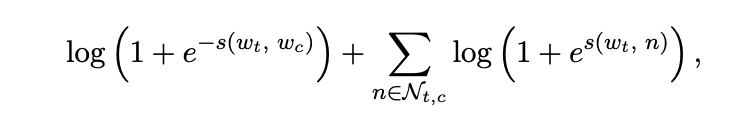
skip-gram을 포함한 word2vec에 관한 자세한 설명은 아래 논문리뷰를 참고 부탁드립니다.
-word2vec(Cbow,skip-gram)
[paper review]Word2Vec: Efficient Estimation of Word Representations in Vector Space
기존의 count based word representaion 방법들은 간단하지만, 단어 간의 유사도를 판단할 수 없습니다. 예를 들면, 삼겹살 [0,0,0,0,0,1] , 목살 [0,0,0,1,0,0] , 연필 [0,1,0,0,0,0] 세 개의 임베딩 된 단어가..
supkoon.tistory.com
-skip-gram의 성능향상(NEG,subsampling,..)에 관한 후속 논문
[paper review] Word2vec: Distributed Representations of Words and Phrases and their Compositionality
본 논문은 이전에 리뷰한 Word2vec의 후속 논문으로 같은해에 발표되었습니다. 따라서 전체적인 개념보다는 이전 논문에서 발표한 Skip-gram 방법론의 representation quality와 computation efficiency 개선을 목
supkoon.tistory.com
2. FastText
단어 내부적인 구조를 보다 잘 반영하기 위하여 FastText는 단어 \(w\)를 n-gram character의 bag으로 표현합니다.
예시를 들어 설명드리도록 하겠습니다.
단어 \(where\) 를 \(n=3\)의 3-gram의 bag으로 표현해 보겠습니다.
우선적으로 각각의 단어는 다른 단어와의 구분을 위하여 앞 뒤로 \(``<"\)와 \(``>"\)가 추가됩니다.
$$where\,\rightarrow\,<where>\,\rightarrow\,<wh,whe,her,ere,re>$$
그리고 여기에 더하여 special sequence로 word \(w\)자체가 포함됩니다. 따라서 bag of n-gram으로 표현된 단어 \(w\)는 다음과 같습니다
$$\mathcal{G_w}\subset\{1,...,G\} = \{<wh,whe,her,ere,re>,<where>\}$$
따라서 이제는 context word와의 score function을 subset \(\mathcal{G_w}\) 의 모든 성분\(\{1,...,G\}\)와 context word 간의 내적들의 합으로 구하게 됩니다.
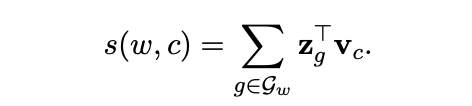
하지만 \(\mathcal{G}\) 를 만드는 것은 데이터의 크기를 분명히 크게 만드는 일 입니다.
저자들은 이러한 계산 효율적 문제를 개선하기 위해 N-gram의 subset을 1에서 K까지의 정수로 mapping 하는 hashing function을 사용하였습니다.
결과적으로 각각의 단어들은 word dictionary에서의 index와 해싱된 n-gram들의 set \(\mathcal{G_w}\) 로 표현이 됩니다.
단어의 Subword 표현을 제외하면, objective function은 기존의 Negative sampling을 사용한 skip-gram과 동일하게 설정됩니다.
3.results
실험은 다섯가지로 진행되었습니다.
1.word similarity
2.word analogy
3.comparison to state-of-art methods
4.training data size
5.N-gram size
result 1.word similarity
word similarity task는 각기 다른 7개의 언어 dataset에 대한 sg(skip-gram), cbow, sisg-,sisg의 성능을
word representation 사이의 cosine similarity와 human judge 간의 Spearman rank correlation, coefficient를 계산하여 비교하였습니다.
sisg-는 OOV words에 대하여 skip-gram, cbow와의 공정한 비교를 위해 똑같이 null vector로 치환한 것이며,
sisg는 OOV words에 대하여도 FastText의 word representation을 적용한 것 입니다.

보시는 것과 같이, EN dataset(english) 한가지를 제외하고는 제안한 sisg 방법이 다른 방법보다 좋은 성능을 보였습니다.
또한, sisg가 sisg-에 비해서 항상 좋은 성능을 보였다는 점에서 subword representation의 효과를 확인할 수 있습니다.
문법적으로 많은 독일어, 러시아어와 같이 어려운 언어에 대해서 더 성능개선이 확실하였으며,
성능이 유일하게 개선되지 않았던 영어에 있어서도 Rare words로 구성된 RW dataset은 성능개선이 확실했다는 부분 또한 주목할 점 입니다.
result 2.word analogy
두번째 실험으로는 analogical reasoning task를 진행하였습니다. word analogy task는 word2vec에서 제안된 실험 방법으로, 단어간의 의미가 vector space에서도 linear하게 잘 보존되는지 확인하는 task 입니다.
예시를 들어 설명하면, 단어간의 의미를 잘 보존하는 word representation은
Angola와 Iran, 그라고 각국의 화폐 kwanza와 rial에 대하여 다음의 관계를 보입니다.
$$W^{'Angola'} + W^{'kwanza'} - W^{'Iran'} \simeq W^{'rial'}$$
따라서 이를 기반으로 다음과 같이 문제를 정의합니다.
$$ Question = X = W^{'Angola'} + W^{'kwanza'} - W^{'Iran'} $$
$$ Answer = y \simeq W^{'rial'} $$
벡터 연산의 결과와 코사인 유사도가 가장 가까운 단어를 맞췄을 때만 정답이라고 인정합니다. 더하여 가장 가까운 단어만을 정답으로 하기에 Synonym들 역시 오답으로 평가하였습니다. 이는 정답률 100퍼센트가 거의 불가능한 문제라고 할 수 있습니다.
본 논문의 저자들은 영어 뿐만이 아니라 다양한 언어에서 실험을 진행하였습니다.

실험 결과 systactic 문제에 있어서는 확실한 성능개선을 보여줬습니다.
하지만 sementic 문제에 있어서는 성능개선이 없었고, 오히려 성능저하를 보인 경우도 있었습니다.
더하여 analogy task에서도 상대적으로 문법적으로 복잡도가 높은 Cs, DE가 좀 더 큰폭의 성능개선을 보였다는 것을 확인할 수 있습니다.
result 3.comparison to state-of-art methods
다양한 state-of-art Model과의 spearman rank correlation coefficient 비교 입니다.
baseline들은 모두 morphology를 고려한 model들 입니다.

다른 모델들에 비해 FastText가 역시 좋은 성능을 보였습니다.
특히 prefix와 suffix를 고려하는 방법은 Och 방법과는 다르게 FastText는 합성어를 표현할 수 있다는 점이 성능차이를 가져왔다고 합니다.
result 4. training data size

모든 경우에서 FastText가 더 우수한 성능을 보였으며, 특히 적은 데이터를 사용했을 때 더 큰 성능차이를 불러왔습니다.
하지만, 지속적으로 성능이 증가하는 Cbow 모델과는 다르게, FastText는 데이터가 증가함에 따라 빠르게 포화되어 성능개선이 수렴해 버리는 추세를 보였습니다.
result 5. N-gram size

task와 언어에 따라 다르겠지만, 대체적으로는 5,6과 같이 긴 n-gram에서 좋은 효과를 보였습니다.
특히 3이상부터 큰 성능개선이 있었는데,
이는 2-gram의 경우에 앞 뒤의 \(``<"\)와 \(``>"\) 로 인해 유의미한 결과를 가져오지 못한 것이라고 저자들은 해석하였습니다.
마무리
FastText는 언어의 구조적 특징을 반영하지 못하는 skip-gram의 단점을 개선하기 위해
\(w\)를 n-gram 단위로 분석하는 subwords를 반영하였습니다.
그 결과 OOV words 혹은 문법적으로 어려운 언어에서 특히 좋은 성능을 얻을 수 있었습니다.
FastText는 2017년 발표된 논문으로 skip-gram방식이 발표된지 거의 4년이 지나 발표된 논문입니다. 정말 좋은 논문임에도 불구하고, word2vec의 문제점에 대해 n-gram이라는 비교적 간단한 해결책을 내놓고 있습니다. 문제상황을 잘 파악하고 그에 알맞는 답안을 제시하는 것이 어쩌면 가장 중요한 문제해결 프로세스가 아닐까 생각이 들었습니다.