tf-idf, word2vec와 같은 Sementic vector space 모델들은 실수 벡터로서 각각의 단어를 표현합니다.
$$V^{류현진} = [0.98,1.0,0.01,1,....,1]$$
$$V^{김태균} = [0.01,0.95,1,0.1,....,0.5]$$
그리고 이러한 vector representation은 information retrieval, document classification, QA 등 다양한 task에 입력으로서 활용됩니다.
다양한 vector representation 품질을 평가하기 위하여 기존에는 단순 scalar 비교 관점인 단어간의 distance,angle 을 활용하였습니다. 하지만, Word2vec의 등장 이후에는 아래 예시와 같이 word pair의 analogies task로서 여러 차원에서 vector representation을 비교하고 의미의 보존 또한 평가할 수 있게 되었습니다.
$$V^{Madrid} - V^{Spain} + V^{France} \simeq V^{Paris}$$
이러한 관점에서 더 좋은 word representation을 찾기 위해 제안된 방법이 바로 GloVe 입니다.
Background
본 논문에서 제안하는 Glove 방법론은 두가지 대중적인 방법론에 motivation을 두고 있습니다.
background 1. local context window (ex: skip-gram)
local context window 방법론은 우리가 잘 알고있는 word2vec 방법론으로서, 전체 corpus에서의 co-occurence를 고려하지 않고 window 내에서의 co-occurence pattern을 분석하는 모델입니다.
자세한 설명은 아래의 글을 참고 부탁드립니다.
-Word2vec(Cbow,skip-gram)
[paper review]Efficient Estimation of Word Representations in Vector Space : Word2Vec
기존의 count based word representaion 방법들은 간단하지만, 단어 간의 유사도를 판단할 수 없습니다. 예를 들면, 삼겹살 [0,0,0,0,0,1] , 목살 [0,0,0,1,0,0] , 연필 [0,1,0,0,0,0] 세 개의 임베딩 된 단어가..
supkoon.tistory.com
-skip-gram 모델의 성능개선에 관한 후속논문
[paper review]Distributed Representations of Words and Phrases and their Compositionality : Word2vec
본 논문은 이전에 리뷰한 Word2vec의 후속 논문으로 같은해에 발표되었습니다. 따라서 전체적인 개념보다는 이전 논문에서 발표한 Skip-gram 방법론의 representation quality와 computation efficiency 개선을 목
supkoon.tistory.com
background 2. Matrix Factorization (ex: LSA)
MF 방법은 선형대수학의 SVD(singular vector decomposition)에 기반을 두고 있는 방법론 입니다.
따로 포스팅을 올리지 않았기 때문에 간단한 설명을 더하면,
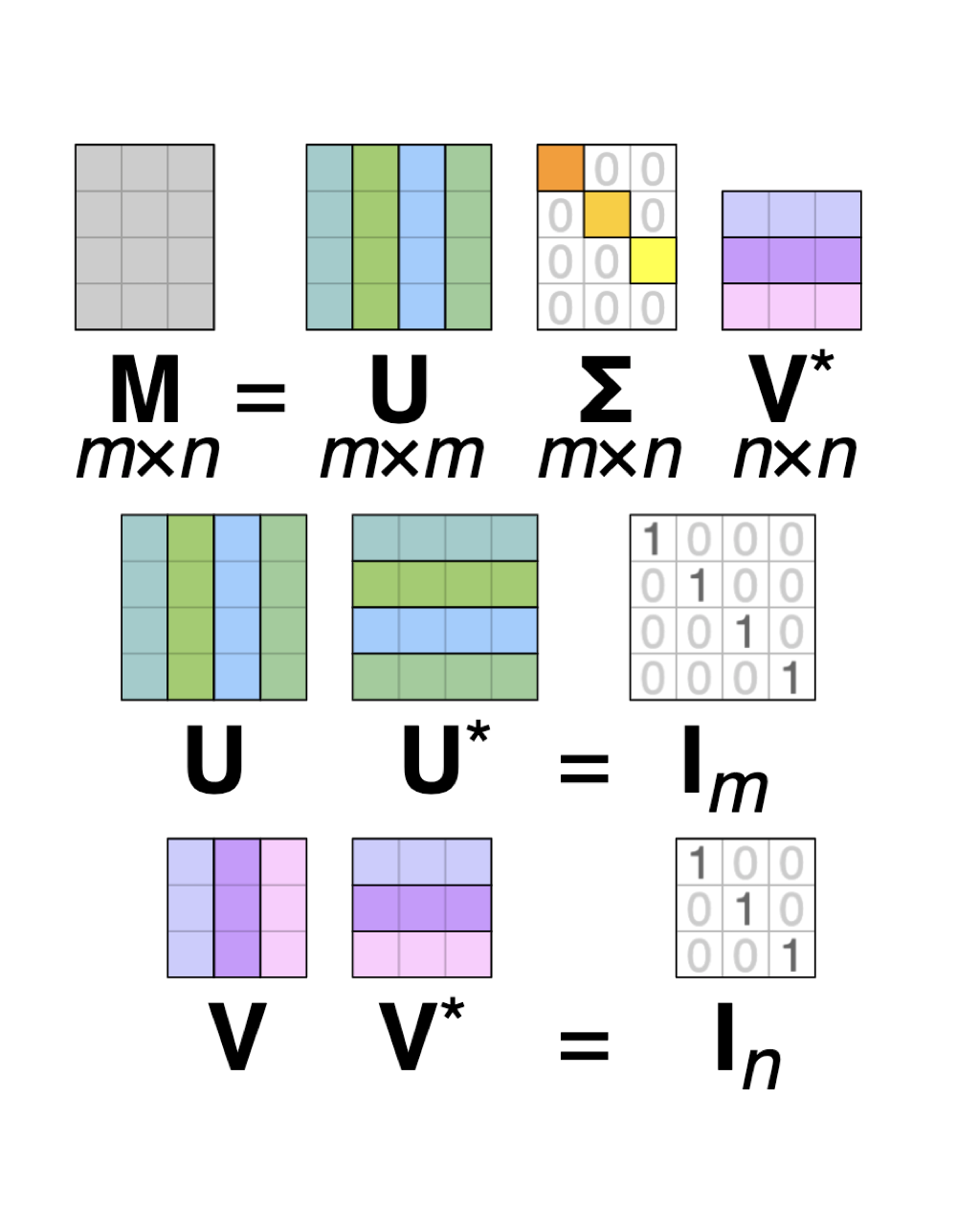
거의 대부분의 경우 위와 같이 문자와 문서의 수가 달라 m x n TDM(term x document matrix) Sementic vector space는 row, column space rank가 다르게 됩니다. \((m \neq n)\)
따라서 정사각 행렬에만 적용할 수 있는 eigen vector decomposition을 수행하기 위해 \(A : m \times n\) 일때 symmetric matrix \(A^TA\,:\,n \times n,\,,AA^T\,:\,m \times m\)를 도입하여 각각의 eigen vector decomposition를 통해 Text 혹은 document를 eigen vector, eigen value로 표현하는 방법론입니다. 보다 자세한 설명은 아래 문서를 참고 부탁드립니다.
Latent semantic analysis - Wikipedia
Latent semantic analysis (LSA) is a technique in natural language processing, in particular distributional semantics, of analyzing relationships between a set of documents and the terms they contain by producing a set of concepts related to the documents a
en.wikipedia.org
GloVe Model
1.GloVe motivation
background model인 MF와 local window 방법은 각각의 장단점을 가지고 있습니다.
MF 방법론은 global co-occurrence matirx를 통하여 전체 corpus의 statistical information을 활용할 수 있다는 장점이 있지만, analogy task에는 좋은 성능을 보이지 못합니다.
반대로 local window 방법론은 analogy task에는 좋은 성능을 보이지만 window 내의 local context만을 학습하기 때문에 전체 corpus의 statistical information을 활용하지 못한다는 단점이 있습니다.
GloVe는 두 모델의 장단점을 활용하여 고안된 방법론 입니다.
notation은 다음과 같습니다.


GloVe는 하나의 통계적인 insight로 부터 출발합니다.
여러 단어간의 의미 관계를 co-occurrence probabilities, notation \(P_{ij}\) 의 관계로 표현할 수 있다는 생각입니다.
위 표의 예시를 들어 설명해 보겠습니다.
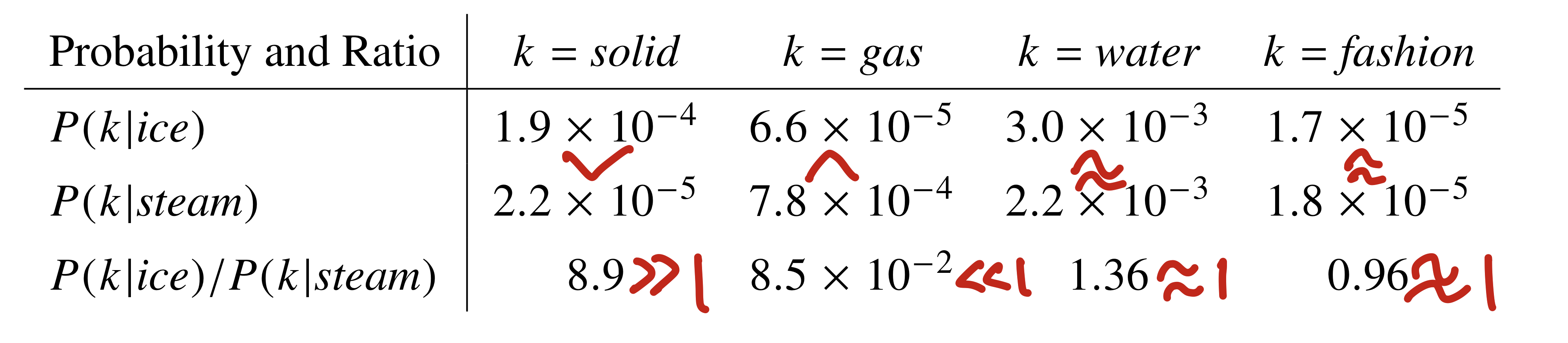
k가 각각 solid, gas, water, fashion 일 때 \(P(k|ice)\) 와 \(P(k|steam)\) 의 대소 관계를 생각해 봅시다.
case 1.k= "solid"
ice는 solid 입니다. 따라서 동시 출현 횟수에 따른 확률값 \(P_{ik}\)의 대소관계는 \(P(solid|ice)\) > \(P(solid|steam)\) 입니다.
따라서 \(P(solid|ice) / P(solid|steam) > 1\) 가 성립합니다.
case 2.k= "gas"
steam은 gas 입니다. 따라서 1번 예시와 반대로 \(P(solid|ice)\) < \(P(solid|steam)\) 입니다.
따라서 \(P(solid|ice) / P(solid|steam) < 1\) 가 성립합니다.
case 3.k="water"
water은 solid와 gas 모두에 관련이 있습니다(either related). 앞선 예시와는 다르게 상대적인 관련성이 치우지지 않아
\(P(solid|ice) \simeq P(solid|steam)\) 입니다.
따라서 \(P(solid|ice) / P(solid|steam) \simeq 1\)가 성립합니다.
case 4.k="fashion"
fashion은 solid와 gas 모두에 관련이 없습니다(neither related). 따라서 역시 상대적으로 \(P(solid|ice) \simeq P(solid|steam)\) 입니다.
역시 \(P(solid|ice) / P(solid|steam) \simeq 1\)가 성립합니다.
위의 4가지 예시를 통해 상대적인 co-occurrence probabilities가 단어간의 의미관계를 나타낼 수 있음을 확인할 수 있습니다.

GloVe가 얻고자 하는 최종 모델 F 또한 이러한 확률 대소관계를 encoding 할 수 있는 모델입니다. 그리고 F로 사용 가능한 모델은 굉장히 많습니다. 하지만 몇가지의 요구조건을 통하여 저자들은 모델 F로 가능한 후보군을 하나로 좁혀갑니다.
2.Finding F(x)
F를 위한 condition 1.
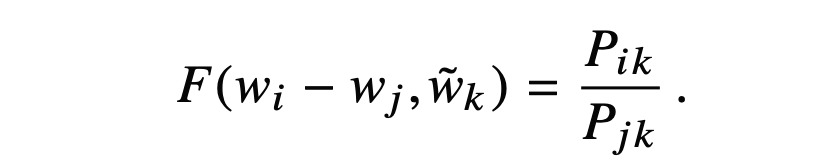
단어 i,j,k의 관계에서 i와 j의 subtraction은 임의의 단어 k에 대한 \(P_{ik} / P_{jk}\) 로 표현되어야 합니다.
F를 위한 condition 2.

condition 1에서의 input은 vector지만 , output은 scaler 형태입니다.
F를 neural network와 같은 복잡한 모델로 차용하면 조건 1과 같은 경우를 설명할 수 있겠지만,
그것은 얻고자 하는 단순한 linear model F가 아닙니다.
따라서 저자들은 condition 1의 input을 내적한 후 F를 적용한 결과가 \(P_{ik} / P_{jk}\)가 되어야 함을 condition 2로 합니다.
F를 위한 condition 3.
$$w \leftrightarrow \tilde{w}$$
F에서 단어의 의미관계는 symmetric 해야합니다. 즉 어떤 단어든 \(w\)와 context word \(\tilde{w}\)가 교환 될 수 있어야하며 결과 역시 같아야 합니다.
$$X \leftrightarrow X^T$$
또한 co-occurence matrix \(X\)는 symmetric하기 때문에 \(X^T\)에 대해서도 적용 될 수 있어야 합니다.
이러한 symmetry를 위하여 F는 아래와 같은 각 group 사이의 homomorphism을 만족해야 합니다.
$$(\mathbb{R},+) \rightarrow (\mathbb{R}_{>0},\times)$$

두가지 input \((ice-steam)^Tsolid , (steam-ice)^Tsolid\)로 예를 들어 설명해 보겠습니다.
F를 적용하기 전 input간의 관계는 실수영역의 덧샘(+)에 대한 역원 관계 입니다.
\((ice-steam)^Tsolid = -(steam-ice)^Tsolid\)
하지만 F를 적용한다면, input간의 관계는 양수 영역의 곱샘(x)에 대한 역원 관계가 되어야 합니다.
\(F((ice-steam)^Tsolid) = {1\over F((steam-ice)^Tsolid)}\)
따라서 일반화 하기 위해
\(A\): \((w_i-w_j)^T\tilde{w_k}\)
\(B\): \({w_j}^T\tilde{w_k}\)
의 경우를 계산하여 보겠습니다.
homomorphism에 따르면
\({w_i}^T\tilde{w_k}\) = \(A + B\) 의 관계가
\(F({w_i}^T\tilde{w_k})\) =\(F(A) \times F(B)\) = \(F((w_i-w_j)^T\tilde{w_k})\times F({w_j}^T\tilde{w_k})\) 를 만족해야 합니다.
$$F({w_i}^T\tilde{w_k}) = F((w_i-w_j)^T\tilde{w_k})\times F({w_j}^T\tilde{w_k})$$
양변을 \(F({w_j}^T\tilde{w_k})\)로 나누어 주면 F는 아래와 같은 식을 만족해야 합니다.

이러한 조건을 만족하는 함수 F는 무엇이 있을까요??
바로 \(F(x) = exp(x)\) 입니다.

또한 condition 2와 condition 3을 종합해 볼때, 아래의 식이 성립하게 됩니다.
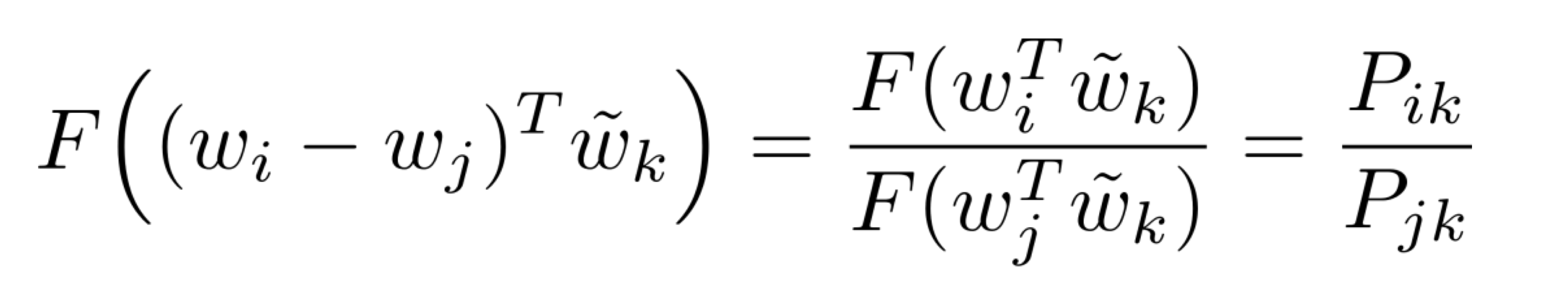

양변에 log를 적용하면 다음의 식이 성립합니다.
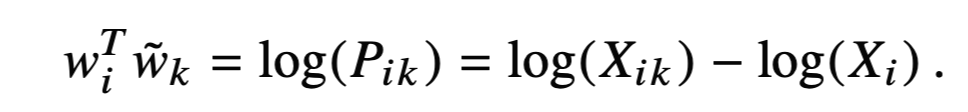
하지만 이 식은 condition 3의 처음에 언급한 i와 k에 대한 symmetric 조건을 만족하지 않습니다.
$$log(X_{ik})-log(X_i) \neq log(X_{ki}) -log(X_k)$$
이기 때문입니다.
저자들은 이러한 부분을 해결하기 위해 상수인 \(log(X_i)\)를 같은 상수항인 \(b_i+\tilde{b_k}\)로 치환합니다.

최종적으로 \(log(X_{ik})\)는 위의 식을 만족합니다.
3.objective function
least square
$$J = \sum_{i,j=1}^V{({w_i}^T\tilde{w_j}+b_i+\tilde{b_j}-log{X_{ij}})}^2$$
weighted least square
$$J = \sum_{i,j=1}^Vf(X_{ij}){({w_i}^T\tilde{w_j}+b_i+\tilde{b_j}-log{X_{ij}})}^2$$
저자들은 목적함수를 위해 일반적인 Least square 방식이 아닌 weighted least square 방법을 사용합니다.
weighted least square는 일반적인 least square 방법에 가중치 함수 f(x)를 도입하여 새로운 목적함수를 더하는 방법입니다.
이 때, f(x)는 희귀하거나 자주 등장하는 조합의 과도한 가중치를 방지하기 위한 적절한 함수가 사용될 수 있습니다.
f(x)가 만족해야 하는 조건들은 다음과 같습니다.
1.f(0) = 0
2.f(x)는 감소하는 형태이면 안된다 => not overweight rare co-occurrences
3.f(x)는 large x에 대하여 상대적으로 작아야한다 => not not overweight frequent co-occurrences


위의 그림은 저자들이 제시한 함수 \(f(X_{ij}\) 입니다.
가중치함수 f(x)를 위한 1,2,3의 조건을 각각 잘 만족함을 알 수 있습니다.
4.results
저자들은 다음 세가지의 실험을 진행하였습니다.
1.word analogy
2.word similarity
3.named entity recognition (NER)
result1. word analogy
저자들은 Word2Vec 논문의 analogical reasoning task를 진행하였습니다. task에 대한 설명은 다시한번 이전 글을 참조해주시면 감사드리겠습니다.
[paper review]Efficient Estimation of Word Representations in Vector Space : Word2Vec
기존의 count based word representaion 방법들은 간단하지만, 단어 간의 유사도를 판단할 수 없습니다. 예를 들면, 삼겹살 [0,0,0,0,0,1] , 목살 [0,0,0,1,0,0] , 연필 [0,1,0,0,0,0] 세 개의 임베딩 된 단어가..
supkoon.tistory.com
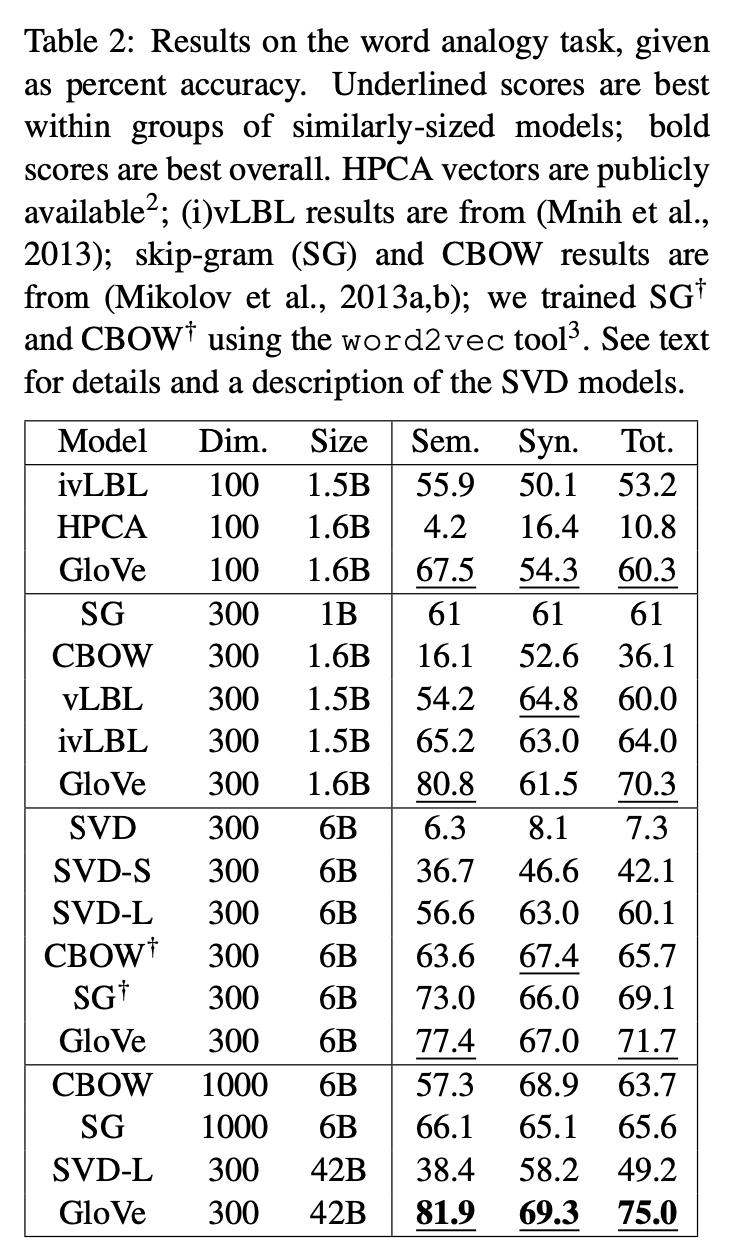
GloVe model이 analogy task에서 다른 baselines 보다 우수한 성능을 보였으며, 심지어 더 작은 vector size와 corpora 에서도 좋은 성능을 보인 경우도 있었습니다.
result 2. word similarity
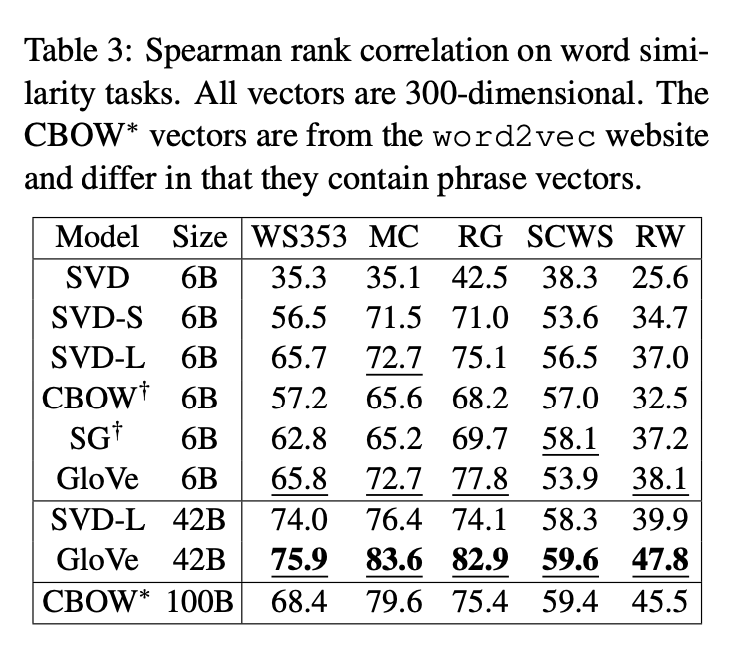
word similarity score는 normalized된 vector의 cosine similarity를 고려하여 계산되었으며, 각기 다른 다섯개의 word similarity dataset에서 진행되었습니다.
위 table은 human judgement와 similarity score의 Spearman rank correlation coefficient 결과를 보여줍니다.
역시 제안한 방법인 GloVe가 CBOW의 절반에 해당하는 training data로 더 좋은 성능을 보였습니다.
result 3. NER

Named entity recognition task는 말 그대로 문장이 주어졌을 때, 해당 문장의 필요한 객체들을 인식하고 알맞는 token을 labeling 해주는 task 입니다.
역시 GloVe 모델이 CoNLL Test set에서의 근소한 차이를 제외하고는 가장 좋은 결과를 불러왔습니다.
따라서 GloVe 모델이 단어간의 훌륭한 의미 보존 뿐만 아니라 downstream task에서도 유용하다는 것을 확인할 수 있습니다.
마무리
GloVe는 FM과 local window based model의 단점을 잘 보완하여 Sementic vector space representation을 제안하였습니다.
FM model의 장점을 고려하여 global corpus의 statistical probability를 고려 하였으며,
window based model을 고려하여 analogy를 잘 수행할 수 있도록 모델링을 하였습니다.
인상적이였던 점은 본인의 objective에 맞는 다양한 조건들을 설정한 후, 그에 맞는 mapping 함수 F와 가중치함수 f를 선택했다는 점 입니다. 실제 연구과정에서는 어떤 순서로 진행이 되었을지 모르지만, 읽는 사람으로 하여금 논리의 흐름을 충분히 납득시켰다는게 대단하다고 느껴졌습니다.
다음 논문으로는 FastText에 대하여 리뷰해보도록 하겠습니다.