신경망 기반의 언어모델에서 양질의 Pre-trained word representation을 사용하는 것은 매우 중요합니다.
잘 학습된 word representation을 사용하는 것은 Down-stream task를 해결하기 위한 key-point로서, 모델의 성능을 끌어 올려줄 수 있는 가장 확실한 방법이기 때문입니다.
하지만, 언어를 벡터로 표현하는 것은 자연어처리 역사의 시작부터 지금까지 두고 두고 남아있는 과제입니다.
언어는 우리의 생각보다도 너무 큰 복잡도를 가지고 있습니다. syntactic, sementic한 특성들은 매우 복잡하게 얽혀 있으며, 언어의 종류에 따라서도 확연하게 달라집니다.
따라서 문법과 같은 복잡한 언어구조를 이해하는 동시에 문맥을 고려한 word representation을 얻는 것은 매우 어려운 일이 됩니다.
예를 들어 우리말 '사과' 는 동음 이의어로 아래와 같이 완전히 다른 의미를 동시에 표현할 수 있습니다.
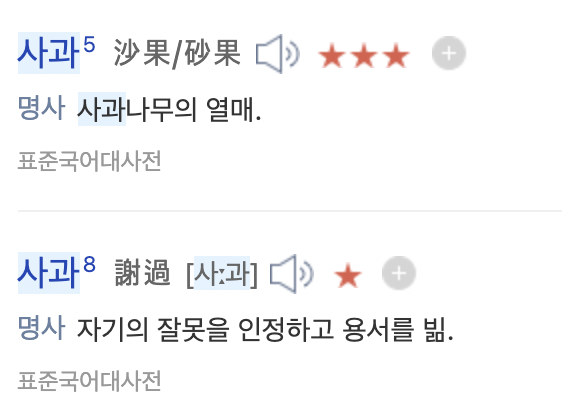
하지만, Word2Vec, Glove와 같은 기존의 word representation 방법에서 각각의 단어는 하나의 벡터로 표현됩니다.
$$V^{사과} = (0.19,1.0,0.5,0.2,...,0.1) $$
사전 학습된 word representation에서 '사과' 라는 단어가 과일에 가깝다면, "사과를 건네다." 라는 문장에 대해서 계산된 벡터 표현이 적절한지에 대해서는 물음표가 따르게 됩니다.
이러한 문제가 발생하는 이유는 word representation이 Context(문맥)를 반영하지 않고 있기 때문입니다.

본 논문은 복잡한 언어의 특성과 문맥적 의미를 동시에 반영할 수 있는 Deep contextuallized word representation ELMo(Embeddings from Language Models)를 제안합니다.
어릴적 친형과 함께 보던 세서미 스트리트의 엘모를 생각하니 마음 한켠이 울적해 집니다. 하지만 세서미 스트리트의 ELMo가 아닙니다.
ELMo는 Word2Vec, GloVe와 같은 전통적인 Word embedding과 다르게 각각의 Token을 모든 input sentence의 함수로 표현하는 word representation 입니다.
ELMo는 기존의 모델들에 쉽게 적용될 수 있으며, down-stream task에 적용되었을 때 놀라운 성능을 발휘하게 됩니다.
1. biLM
ELMo에 대하여 설명 드리기에 앞서, ELMo는 biLM(bidirectional language model)이라는 구조를 바탕으로 계산됩니다.
biLM은 N개의 tokens \((t_1,t_2,..,t_N)\) 으로 이루어진 Sequence를 input으로 양 방향(forward,backward)의 Language model을 통해 해당 Sequnece의 확률을 예측하는 모델입니다.
biLM의 input token \(t_k\)는 일반적으로 context-independent word representation \(X_k^{LM}\)가 사용됩니다. 따라서 Word2Vec, GloVe, fasttext와 같은 token embedding 방법들이 사용될 수 있습니다.
우선 forward LM은 Token Sequence의 확률을 계산할 때, token \(t_k\)의 확률을 이전 token들 \((t_1,...,t_{k-1})\)을 활용하여 모델링합니다.

반대로 backward LM은 Token Sequence의 확률을 계산할 때, token \(t_k\)의 확률을 k 시점 이후의 token들 \((t_{k+1},...,t_N)\)을 활용하여 모델링합니다.
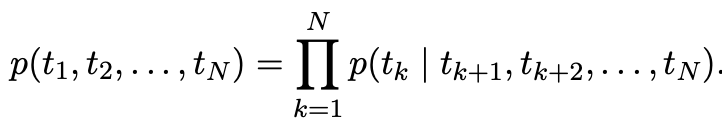
biLM의 학습은 위의 forward, backward Language Model을 합쳐 함께 확률을 최대화 하는 방법으로 진행됩니다.
$$\sum_{k=1}^N{(logp(t_k| t_1,...,t_{k-1};\theta) + logp(t_k|t_{k+1},...,t_N;\theta)) }$$
L개 layer의 forward, backward LM을 각각 통과한 token k는 이러한 log-likelihood의 최대화 과정을 통하여
\(j\) 번째 LM layer \((j = 1,...,L)\)의 context-dependent word representation인 \(\overrightarrow{h_{k,j}^{LM}}\), \(\overleftarrow{h_{k,j}^{LM}}\)를 학습할 수 있습니다.
따라서 token \(k\)에 대해서 biLM은 아래의 2L+1 개 representation \(R_k\)를 계산합니다.
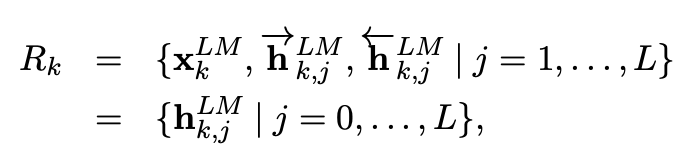
Embedding 층을 \(h_{k,0}^{LM}\)으로 정의하면 layer j에 대한 representation은 \(h_{k,j}^{LM}\)으로 일반화가 가능합니다.
하지만, 일반적인 biLM 구조에서는 LM의 맨 윗 layer \(L\)로 부터 얻은 representation \(\overrightarrow{h_{k,L}^{LM}}\), \(\overleftarrow{h_{k,L}^{LM}}\) 만을 down-stream task를 위해 사용합니다.
2. ELMo
ELMo는 LSTM을 사용하여 biLM을 구성합니다.
ELMo는 이런 biLSTM Layer들의 representation \(h_{k,j}^{LM}\)을 linear combination(선형결합)하는 방법으로 각각의 단어를 표현합니다.
그렇기 때문에 ELMo는 lower-layer의 syntax 정보부터 higher-layer의 context 정보까지 반영하는 Deep contextuallized word representation을 만들 수 있게 됩니다.
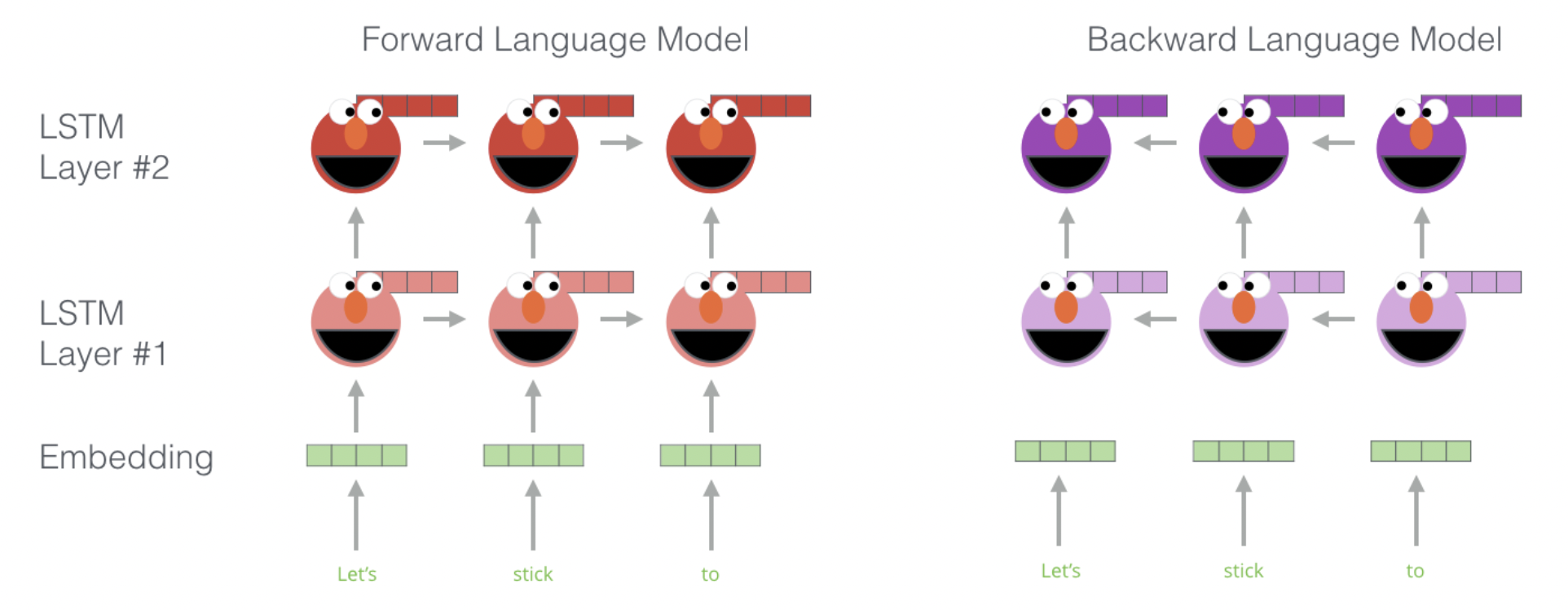
보다 자세한 방법은 다음과 같습니다.
위의 그림과 같이 biLSTM은 input sentence의 각각의 단어 위에 word Embedding 층을 시작으로 biLSTM이 stack되어 있는 구조입니다.
token \(k\)에 대한 ELMo representation은 아래와 같이 task에 따른 layer j의 softmax 가중치 \(s_j^{task}\)를 이용해 \(h_{k,j}^{LM}\)를 선형결합하여 single Vector로 표현됩니다.
\(\gamma^{task}\)는 전체 ELMo vector의 크기를 scaling 해주는 scalar parameter 입니다.


Objective function of biLM
ELMo를 위한 biLM의 목적함수는 아래의 log-likelihood를 최대화 하는 것 입니다.

forward, backward LSTM이 token embedding \(\theta_x\)와 softmax layer \(\theta_s\)를 공유하기 때문에 위와 같은 log-likelihood로 표현할 수 있습니다.
ELMo Applications
pretrained biLM이 있다면, 지도학습 형태의 down stream task 모델이 있을 때, biLM을 적용하는 것은 매우 간단합니다.
우선 pretrain된 biLM에 해당 task의 sequence를 통과시켜 각각 단어 k에 대한 layer representation \(h_{k,j}^{LM}\)를 계산합니다.
그리고 biLM을 통한 2L+1 개의 layer representation을 모두 계산하였다면, biLM의 가중치들을 더이상 학습하지 않도록 freeze 합니다.
biLM의 가중치를 freeze 하였다면, 이제 ELMo를 추가한 지도학습 down stream task model을 학습하여 task specific한 softmax 가중치 \(s_j^{task}\)를 얻을 수 있습니다.
지도학습 모델에 ELMo를 추가하기 위한 방법은 Word2Vec, GloVe와 같은 context-independent word representation \(X_k\)에 ELMo representation \(ELMo_k^{task}\)를 concatenate 하는 것 입니다.
즉, ELMo enhanced representation \([x_k;ELMo_k^{task}]\) 를 model에 input 해주는 것이 지도학습 down stream task에 ELMo를 적용하는 주된 방법입니다.
Regularizations
Regularization을 위한 방법으로 dropout을 추가하고, l2 정규화인 \(\lambda||w||_2^2\)항을 손실함수에 추가합니다.
이러한 과정을 통해 보다 양질의 ELMo representation을 얻어 down stream task의 성능을 향상시킬 수 있습니다.
3.results
result 1.

첫 번째 실험은 여섯개의 NLP benchmark task에 ELMo를 적용한 결과를 보여줍니다.
각각의 task는 차례대로 QA task, Textual entailment, Sementic role labeling, Coreference resolution, Named entity extraction, Sentiment analysis의 benchmark task 입니다.
task에 따라 다른 metric이 사용되었지만, 모든 분야에서 ELMo를 추가한 결과 SOTA를 달성할 수 있었습니다.
result 2.

regularization parameter \(\lambda\)에 따른 성능 비교입니다.
모든 biLM layer를 사용하여 ELMo를 표현하고 적절한 \(lambda\)를 적용하였을 때 가장 좋은 성능을 보였습니다.
result 3.

ELMo representation이 추가되는 위치에 따른 성능 비교입니다.
단순히 input의 위치에서만 ELMo를 추가하는 것이 아닌, 입,출력 동시에 추가했을 경우, 출력에만 추가했을 경우를 비교하였습니다.
세가지 Task의 결과가 일치되지는 않았지만 대체로 입,출력에 모두 ELMo를 적용한 모델 성능이 좋았습니다.
하지만 이를 통해, Task 별로 ELMo representation이 필요한 위치가 다름을 직관적으로 알 수 있습니다.
result 4.

play 라는 단어에 대한 GloVe와 biLM의 representation vector를 통하여 유사한 단어들을 확인해본 결과 입니다.
GloVe의 결과는 스포츠와 관련된 단어들이 주를 이뤘습니다. 그리고 GloVe는 하나의 단어에 대해 하나의 벡터 표현만을 갖고 있기 때문에 같은 play를 유사한 단어로 추천하지 않았습니다.
반면에 biLM의 play는 각각 다른 문맥에서 주어진 play와 의미가 일치하는 play를 각각 유사한 단어로 추천한 결과를 확인할 수 있습니다.
result 5,6

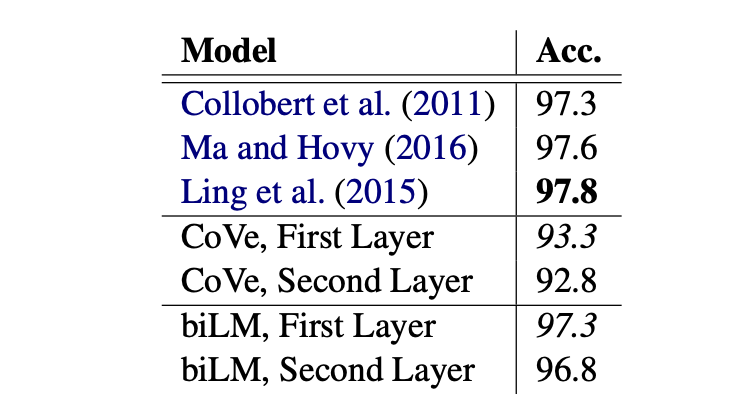
왼쪽은 Context 능력이 중요한 Word sense disambiguation(WSD, 단어 의미 중의성해소) task의 결과이며,
오른쪽은 Syntax 능력이 중요한 Pos tagging task의 결과 입니다.
우선, 두 실험에서 모두 biLM이 준수한 성능을 보였음을 확인할 수 있습니다.
본 실험을 통해 알 수 있는 중요한 정보가 있습니다.
WSD의 경우, First layer를 이용한 것 보다 Second layer를 이용한 성능이 좋았기 때문에 higer-layer가 context 파악에 있어 더 중요한 정보를 제공 한다는 것을 확인할 수 있었습니다.
또한, POS-tagging에 있어서는 First layer를 사용한 성능이 더 좋았다는 점에서 lower-layer가 Syntax를 파악에 있어 더 중요한 정보를 제공한다는 것을 확인할 수 있었습니다.
result 7.

train set의 크기에 따른 성능 비교입니다.
학습데이터가 작을수록 ELMo를 사용하면 더 효율적인 학습이 가능함을 확인할 수 있습니다.
result 8.

task의 Input Layer와 Output Layer가 더 높은 가중치를 두는 biLM layer를 확인하기 위한 시각화 결과입니다.
Input Layer는 상대적으로 첫번째 layer에 높은 가중치를 두었으며,
Output Layer는 상대적으로 모든 layer에 대해 균형잡힌 가중치를 두고 있음을 확인할 수 있습니다.
마무리
ELMo는 BiLM의 hidden layer를 선형결합하여 얻을 수 있는 context-dependent word representation입니다.
다양한 실험을 통하여 ELMo를 downstream task에 적용할 시 언어의 context를 고려할 수 있고, syntacic, sementic 특성을 잘 반영할 수 있음을 확인할 수 있었습니다.
ELMo는 또한 Attention을 활용한 모델이 아님에도 Bert와 같은 해에 발표되어 다양한 task에서 매우 우수한 성능을 보였습니다.
논문을 읽으며 ELMo는 생각보다 간단한 방법이지만, 직관적으로 납득이 가는 방법이라는 생각이 들었습니다.
또한 굉장히 많은 실험을 통해 다양한 각도에서 모델의 특징을 파악한 점이 좋았던 것 같습니다.
다음 시간에는 BERT 모델에 대하여 리뷰해 보도록 하겠습니다.